Co je API?
Klient a server
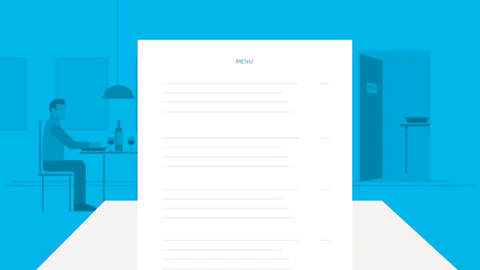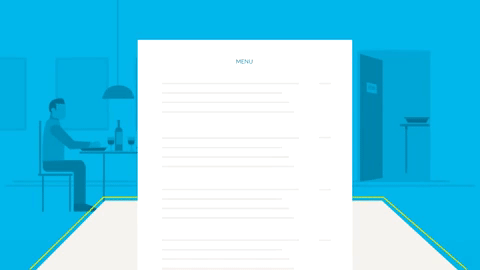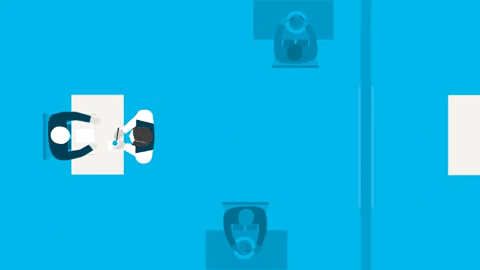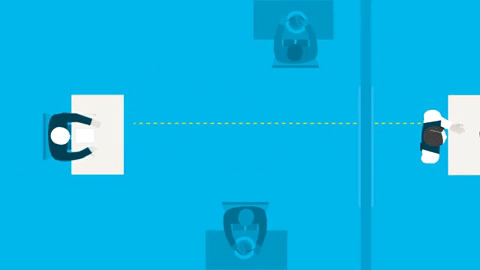
API (Application Programming Interface) je dohoda mezi dvěma stranami o tom, jak si mezi sebou budou povídat. Těmto stranám se říká klient a server.
Server je ta strana, která má zajímavé informace nebo něco zajímavého umí a umožňuje ostatním na internetu, aby toho využili. Server je program, který donekonečna běží na nějakém počítači a je připraven všem ostatním na internetu odpovídat na požadavky.
Klient je program, který posílá požadavky na server a z odpovědí se snaží poskládat něco užitečného. Klient je tedy mobilní aplikace s mráčky a sluníčky nebo náš prohlížeč, v němž si můžeme otevřít kurzovní lístek ČNB. Je to ale i Heureka robot, který za Heureku načítá informace o zboží v e-shopech.
Serverové straně se v těchle materiálech nebudeme věnovat. Koho by to zajímalo, nechť se podívá na cojeapi.cz
Základní pojmy
Než se pustíme do tvorby klienta, projdeme si některé základní pojmy kolem API.
Protokol
Celé dorozumívání mezi klientem a serverem se odehrává přes tzv. protokol. To není nic jiného, než smluvený způsob, co bude kdo komu posílat a jakou strukturu to bude mít. Protokolů je v počítačovém světě spousta, ale nás bude zajímat jen HTTP, protože ten využívají webová API a ostatně i web samotný. Není to náhoda, že adresa internetových stránek v prohlížeči zpravidla začíná http:// (nebo https://).
HTTP
Dorozumívání mezi klientem a serverem probíhá formou požadavku (HTTP request), jenž posílá klient na server, a odpovědi (HTTP response), kterou server posílá zpět. Každá z těchto zpráv má své náležitosti.
Požadavek
- metoda (HTTP method): Například metoda GET má tu vlastnost, že pouze čte a nemůžeme s ní tedy přes API něco změnit - je tzv. bezpečná. Kromě metody GET existují ještě metody POST (vytvořit), PUT (aktualizovat) a DELETE (odstranit), které nepotřebujeme, protože data z API budeme pouze získávat.
- adresa s parametry (URL s query parameters): Na konci běžné URL adresy otazník a za ním parametry. Pokud je parametrů víc, oddělují se znakem &. Adresa samotná nejčastěji určuje o jaká data půjde (v našem příkladě jsou to filmy) a URL parametry umožňují provést filtraci už na straně serveru a získat tím jen ta data, která nás opravdu zajímají (v našem případě dramata v délce 150 min)
http://api.example.com/movies/ http://api.example.com/movies?genre=drama&duration=150 - hlavičky (headers): Hlavičky jsou vlastně jen další parametry. Liší se v tom, že je neposíláme jako součást adresy a na rozdíl od URL parametrů podléhají nějaké standardizaci a konvencím.
- tělo (body): Tělo zprávy je krabice, kterou s požadavkem posíláme, a do které můžeme vložit, co chceme. Tedy nejlépe něco, čemu bude API na druhé straně rozumět. Tělo může být prázdné. V těle můžeme poslat obyčejný text, data v nějakém formátu, ale klidně i obrázek. Aby API na druhé straně vědělo, co v krabici je a jak ji má rozbalovat, je potřeba s tělem zpravidla posílat hlavičku Content-Type.
Musíme vyčíst z dokumentace konkrétního API, jak požadavek správně poskládat.
Odpověď
- status kód (status code): Číselný kód, kterým API dává najevo, jak požadavek zpracovalo. Podle první číslice kódu se kódy dělí na různé kategorie:
1xx - informativní odpověď (požadavek byl přijat, ale jeho zpracování pokračuje) 2xx - požadavek byl v pořádku přijat a zpracován 3xx - přesměrování, klient potřebuje poslat další požadavek jinam, aby se dobral odpovědi 4xx - chyba na straně klienta (špatně jsme poskládali dotaz) 5xx - chyba na straně serveru (API nezvládlo odpovědět) - hlavičky (headers): Informace o odpovědi jako např. datum zpracování, formát odpovědi...
- tělo (body): Tělo odpovědi - to, co nás zajímá většinou nejvíc
Formáty
Tělo může být v libovolném formátu. Může to být text, HTML, obrázek, PDF soubor, nebo cokoliv jiného. Hodnotě hlavičky Content-Type se dávají různé názvy: content type, media type, MIME type. Nejčastěji se skládá jen z typu a podtypu, které se oddělí lomítkem. Několik příkladů:
- text/plain - obyčejný text
- text/html - HTML
- text/csv - CSV
- image/gif - GIF obrázek
- image/jpeg - JPEG obrázek
- image/png - PNG obrázek
- application/json - JSON
- application/xml nebo text/xml - XML
Formát JSON
JSON vznikl kolem roku 2000 a brzy se uchytil jako stručnější náhrada za XML, především na webu a ve webových API. Dnes je to nejspíš nejoblíbenější formát pro obecná strukturovaná data vůbec. Jeho autorem je Douglas Crockford, jeden z lidí podílejících se na vývoji jazyka JavaScript.
Jeho oblíbenost pramení nejspíš i z jeho jednoduchosti. Ostatně tenhle jupyter notebook je uložen ve formátu JSON. Jeho plná specifikace je popsaná pomocí několika diagramů na stránce json.org.
JSON je datový formát NE datový typ!
Vstupem je libovolná datová struktura:
- číslo
- řetězec
- pravdivostní hodnota
- pole
- objekt
- None
Výsutpem je vždy řetězec (string)

Jazyk Python (a mnoho dalších) má podporu pro práci s JSON v základní instalaci (vestavěný).
V případě jazyka Python si lze JSON splést především se slovníkem (dictionary). Je ale potřeba si uvědomit, že JSON je text, který může být uložený do souboru nebo odeslaný přes HTTP, ale nelze jej přímo použít při programování. Musíme jej vždy nejdříve zpracovat na slovníky a seznamy.
import json
V následujícím JSONu je pod klíčem "people" seznam slovníků s další strukturou:
people_info = '''
{
"people": [
{
"name": "John Smith",
"phone": "555-246-999",
"email": ["johns@gmail.com", "jsmith@gmail.com"],
"is_employee": false
},
{
"name": "Jane Doe",
"phone": "665-296-659",
"email": ["janed@gmail.com", "djane@gmail.com"],
"is_employee": true
}
]
}
'''
json.loads převede řetězec na objekt
data = json.loads(people_info)
type(data)
type(data['people'])
type(data['people'][0])
data['people']
data['people'][0]
data['people'][0]['name']
Práce s API klienty
Obecný klient
Mobilní aplikace na počasí je klient, který někdo vytvořil pro jeden konkrétní úkol a pracovat umí jen s jedním konkrétním API. Takový klient je užitečný, pokud chceme akorát vědět, jaké je počasí, ale už méně, pokud si chceme zkoušet práci s více API zároveň. Proto existují obecní klienti.
Prohlížeč jako obecný klient
Pokud z API chceme pouze číst a API nevyžaduje žádné přihlašování, můžeme jej vyzkoušet i v prohlížeči, jako by to byla webová stránka. Pokud na stránkách ČNB navštívíme kurzovní lístek a úplně dole klikneme na Textový formát, uvidíme odpověď z API serveru
Obecný klient v příkazové řádce: curl
Pokud se k API budeme potřebovat přihlásit nebo s ním zkoušet dělat složitější věci než jen čtení, nebude nám prohlížeč stačit.
Proto je dobré se naučit používat program curl. Spouští se v příkazové řádce a je to švýcarský nůž všech, kteří se pohybují kolem webových API.
Příklady s curl

Když příkaz zadáme a spustíme, říkáme tím programu curl, že má poslat požadavek na uvedenou adresu a vypsat to, co mu ČNB pošle zpět.
Vlastní klient
Obecného klienta musí ovládat člověk (ruční nastavování parametrů, pravidelné spuštění na základě podmínek či času atd.). To je přesně to, co potřebujeme, když si chceme nějaké API vyzkoušet, ale celý smysl API je v tom, aby je programy mohly využívat automaticky. Pokud chceme naprogramovat klienta pro konkrétní úkol, můžeme ve většině jazyků použít buď vestavěnou, nebo doinstalovanou knihovnu. V případě jazyka Python použijeme knihovnu Requests.
Každé slušné API má dokumentaci, kde je popsáno celé fungování API. Tedy všechny možné url (endpointy), metody, parametry, formáty, chybové kódy atd. Dokumentace může mít formu webové stránky jako na příkladu dat od britské policie, které za chvíli použijeme. Velmi často používaným způsobem popisu API je také OpenAPI (dříve Swagger). API je pomocí tohoto standardu popsáno v textovém formátu, který jde pak vizualizovat jako na příkladu tohohle smyšleného Zverimexu.
Práce s veřejným API
Vyzkoušíme si dotazy na API s daty zločinnosti v UK, která jsou dostupná na měsiční bázi dle přibližné lokace (viz https://data.police.uk/docs/method/stops-at-location/)
import requests
api_url = "https://data.police.uk/api/stops-street"
Nastavení parametrů volání API dle dokumentace https://data.police.uk/docs/method/stops-at-location/ Jako lokaci jsem vybral nechvalně proslulý obvod Hackney v Londýně :)
params = {
"lat" : "51.5487158",
"lng" : "-0.0613842",
"date" : "2018-06"
}
Pomocí funkce get pošleme požadavek na URL adresu API. URL adresa doplněná o parametry vypadá takto: https://data.police.uk/api/stops-street?lat=51.5487158&lng=-0.0613842&date=2018-06 a je možné ji vyzkoušet i v prohlížeči.
V proměnné response máme uložený objekt, který obsahuje odpověď od API.
response = requests.get(api_url, params=params)
Pokud je status kód jiný, než 200 (success), vyhodí skript chybu a chybový status code
if response.status_code != 200:
print('Failed to get data:', response.status_code)
else:
print('First 100 characters of data are')
print(response.text[:100])
Hlavička s doplňujícími informacemi o opdovědi
response.headers
response.headers['content-type']
Obsah odpovědi je řetězec bytů
response.content[:200]
Vypadá jako seznam (list) nebo slovník (dictionary), ale nechová se tak:
response[0]["age_range"]
Převedeme řetězec bytů metodou .json() z knihovny requests
data = response.json()
Ověříme datový typ
type(data)
Nyní můžeme přistupovat k "data" jako ke klasickému seznamu (list)
data[0]["age_range"]
Převední seznamu(list) na řetězec s parametry pro zobrazení struktury v čitelné podobě
datas = json.dumps(data, sort_keys=True, indent=4)
print(datas[:1600])
Cyklus, kterým přistupujeme k věkovému rozpětí lidí lustrovaných policií
age_range = [i["age_range"] for i in data]
print(age_range)
Cyklus, kterým přistupujeme k id ulice, kde došlo lustraci podezřelé(ho)
street_id = [i["location"]["street"]["id"] for i in data]
print(street_id)
import pandas as pd
Spojíme seznamy do dataframe
df_from_lists = pd.DataFrame(list(zip(age_range, street_id)),
columns = ['age_range', 'street_id'])
df_from_lists.head()
Jakou věkovou skupinu lustrovala policie nejčastěji?
%matplotlib inline
df_from_lists["age_range"].value_counts().plot.bar();

Json_normalize
aneb jak jednoduše převést JSON na DataFrame
data
from pandas.io.json import json_normalize
norm_data = json_normalize(data)
norm_data.head()
norm_data["gender"].value_counts()
norm_data["gender"].value_counts().plot.bar();

norm_data["age_range"].value_counts().plot.bar();
Tvoříme klienta pro práci s veřejným API
V následujícím bloku si vytvoříme klienta, který nám stáhne data za dva měsíce (místo jednoho) a uloží je do seznamu seznamů (list of lists). Případné chyby spojení s API ošetříme výjimkami (exceptions) - více viz dokumentace requests
def get_uk_crime_data(latitude, longitude, dates_list):
"""
Function loops through a list of dates
Three arguments latitude, longitude and a list of dates
Returns a dataframe with crime data for each day
"""
appended_data = []
for i in dates_list:
api_url = "https://data.police.uk/api/stops-street"
params = {
"lat" : latitude,
"lng" : longitude,
"date" : i
}
response = requests.get(api_url, params=params)
data_foo = response.json()
data = pd.json_normalize(data_foo)
# store DataFrame in list
appended_data.append(data)
return pd.concat(appended_data)
Zavolání funkce get_uk_crime_data s parametry zeměpisné šíře a délky přiřazené proměnné df_uk_crime_data
dates_list = ["2018-06","2018-07"]
lat = "51.5487158"
lng = "-0.0613842"
df_uk_crime_data = get_uk_crime_data(lat, lng, dates_list)
df_uk_crime_data.head()
Přistupování k tweetům přes Twitter API pomocí knihovny Tweepy
Příkaz na instalaci knihovny tweepy uvnitř notebooku. Stačí odkomentovat a spustit.
#%pip install tweepy
import tweepy
Pro získání dat z Twitteru musí náš klient projít OAuth autorizací.
Jak funguje OAuth autorizace na Twitteru?
- vývojář aplikace se zaregistruje u poskytovatele API
- zaregistruje aplikaci, získá consumer_key, consumer_secret, access_token a access_secret na https://developer.twitter.com/en/apps
- aplikace volá API a prokazuje se consumer_key, consumer_secret, access_token a access_secret
consumer_key = ""
consumer_secret = ""
access_token = ""
access_secret = ""
Další krok je vytvoření instance OAuthHandleru, do kterého vložíme náš consumer token a consumer secret
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
Ověření funkčnosti autentifikace
api = tweepy.API(auth)
try:
api.verify_credentials()
print("Authentication OK")
except Exception:
print("Error during authentication")
V API dokumentaci k Tweepy http://docs.tweepy.org/en/v3.5.0/api.html najdeme metodu která např. vypíše ID přátel, resp. sledujících účtu
api.friends_ids('@kdnuggets')
Nebo vypíše ID, které účet sleduje
api.followers_ids('@kdnuggets')
Metoda, která vrátí posledních 20 tweetů podle ID uživatele
twitter_user = api.user_timeline('@kdnuggets')
kdnuggets_tweets = [i.text for i in twitter_user]
print(kdnuggets_tweets)
def get_tweets(consumer_key, consumer_secret, access_token, access_secret, twitter_account):
"""
Function gets the last 20 tweets and adds those not in the list
Five arguments consumer_key, consumer_secret, access_token, access_secret, and twitter_account name
Returns a dataframe with tweets for given account
"""
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
try:
api.verify_credentials()
print("Authentication OK")
twitter_user = api.user_timeline(twitter_account)
tweets_list = [i.text for i in twitter_user]
except Exception:
print("Error during authentication")
return pd.DataFrame(tweets_list, columns = [twitter_account])
get_tweets(consumer_key, consumer_secret, access_token, access_secret, '@kdnuggets')
Tweety můžeme vyhledávat i podle hashtagu!
for tweet in api.search('#masks4all'):
print(tweet.user.screen_name, tweet.text)
print('---')
Takhle ale dostaneme jenom 20 posledních tweetů. Pokud by nám to nestačilo, tak podle dokumentace k metodě search můžeme nastavit return per page rpp=30, to jde ale nastavit maximálně na hodnotu 100. Pokud bychom chtěli víc, potřebujeme procházet výsledky po stránkách. Tedy nastavovat parametr page=2 a postupně procházet cyklem. Stránky se tu číslují od jedné.