EDA - Pandas profiling
Asi nikoho nepřekvapí, že existuje spousta automatických nástrojů, které dokáží datovým analytikům usnadnit práci. O co snazší je dostat s jejich pomocí z dat spoustu čísel, grafů a informací, o to větší pozornost se musí věnovat jejich správné interpretaci. Proto si o jednom z nich budeme povídat až na samotném konci explorační datové analýzy, když už umíme jednotlivé charakteristiky získat i ručně a správně je interpretovat, díky čemuž se v bohatých automatických reportech neztratíme.
Jedním z nástrojů pro automatické reporty je Pandas Profiling.
Pandas Profiling si stejně jako ostatní knihovny musíme nejdříve nainstalovat. V jedné z prvních lekcí jsme zjistili, že příkazy příkazové řádky lze spouštět i přímo z notebooku, tak toho můžeme zkusit využít.
Příprava prostředí a instalace knihoven standardně nebývá součástí notebooků a provádí se ještě před jeho spuštěním, takže to ber jako netradiční využití a spíše jako ukázku možností.
!python -m pip install pandas-profiling
Dynamický výstup v tomto případě není příliš přehledný a kromě seznamu všech instalovaných závislostí neobsahuje nic užitečného, takže jej pro tentokrát z notebooku vynecháme.
Data k analýze jsou připravena v souboru spotify_top10.csv a obsahují informace o nejpopulárnějších skladbách ve službě Spotify v letech 2010-2019. Data byla publikována na kaggle.com a jejich původní zdroj je tato část služby Spotify.
Generování reportu lze provést buď samostatně mimo notebook a v tom případě bude výsledkem samostatný HTML soubor s reportem, nebo v notebooku, kdy se výsledky zobrazí přímo uvnitř notebooku. My použijeme první variantu, protože je rychlejší a přehlednější.
Stejně jako v předchozím případě lze tento příkaz spustit přímo v příkazové řádce a notebook k němu není vůbec potřeba.
!pandas_profiling static/spotify_top10.csv static/spotify_report.html
Pokud máš na počítači procesor s více jádry, je možné parametrem --pool_size X nastavit, aby pandas_profiling zpracovával data paralelně na X jádrech a tím lépe využil výpočetní výkon tvého počítače a zkrátil dobu zpracování.
A teď už k samotnému reportu, který je dostupný na této stránce.
Úplně nahoře je navigační pruh, který nám usnadní navigaci v dlouhém reportu a zrychlí přepínání mezi jednotlivými částmi, na které se teď podíváme postupně.
Část první - Obecné informace (Overview)
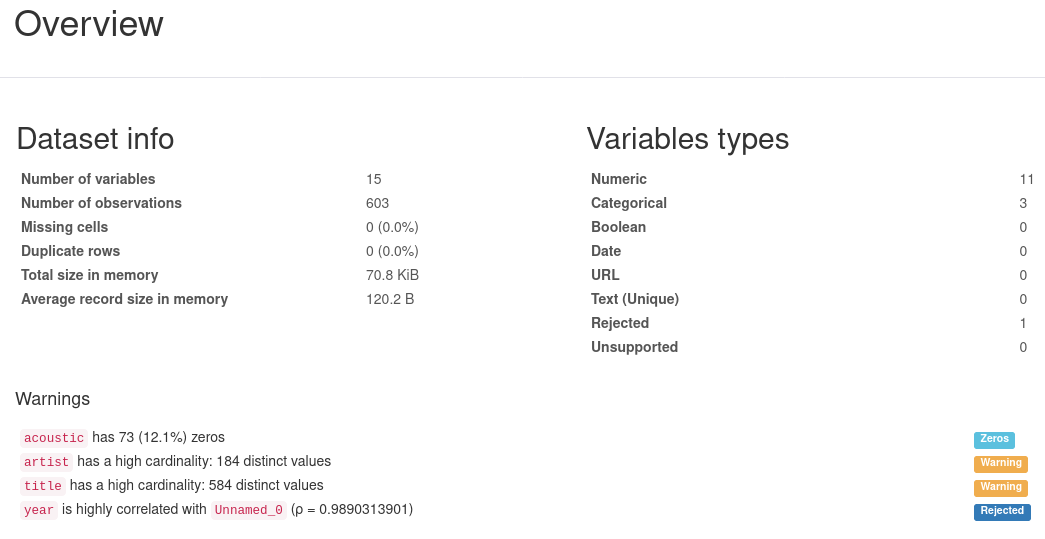
První část obsahuje v levém sloupci obecné informace o celém datasetu a v pravém sloupci pak informace o jednotlivých proměnných a identifikovaných typech. Zajímavé je si všimnout, že jedna proměnná byla z analýzy automaticky vyřazena. Proč se tak stalo, se dozvíme o kousek níže v sekci s informacemi a varováními. Ta nejčastěji obsahuje upozornění na příliš mnoho nulových hodnot nebo naopak příliš mnoho jedinečných hodnot u kategoriálních proměnných. Stejně jako v tomto případě je zde i důvod vyřazení sloupce year pro příliš vysokou korelaci s nepojmenovaným sloupcem. Tady je vidět první chyba. Zatímco my bychom raději vyřadili první nepojmenovaný sloupec obsahující index, automatika se rozhodla jinak.
Část druhá - Proměnné (Variables)
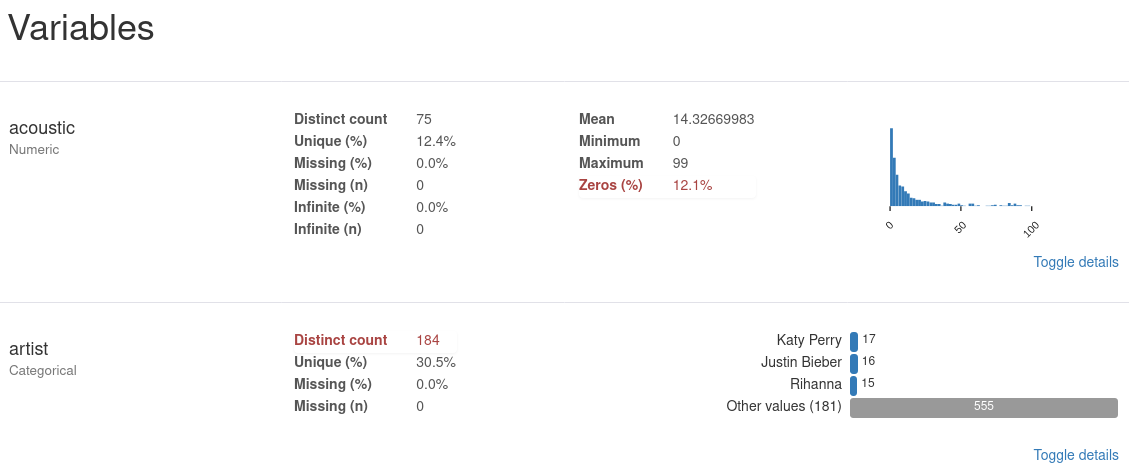
Druhá část obsahuje informace pro jednotlivé sloupce. Množství a podoba poskytnutých informací záleží na typu proměnné. U každé proměnné je možné si rozbalit další podrobnosti odkazem v pravém dolním rohu (Toggle details) a dostat tak podrobnější informace. U numerických proměnných jsou to podrobnější popisné statistiky, histogramy a nejběžnější a extrémní hodnoty. U kategoriálních proměnných jsou to podrobnější informace o nejčastějších hodnotách a dalších vlastnostech popisující souhrnně vyskytující se hodnoty (Composition).
Část třetí - Korelace (Correlations)
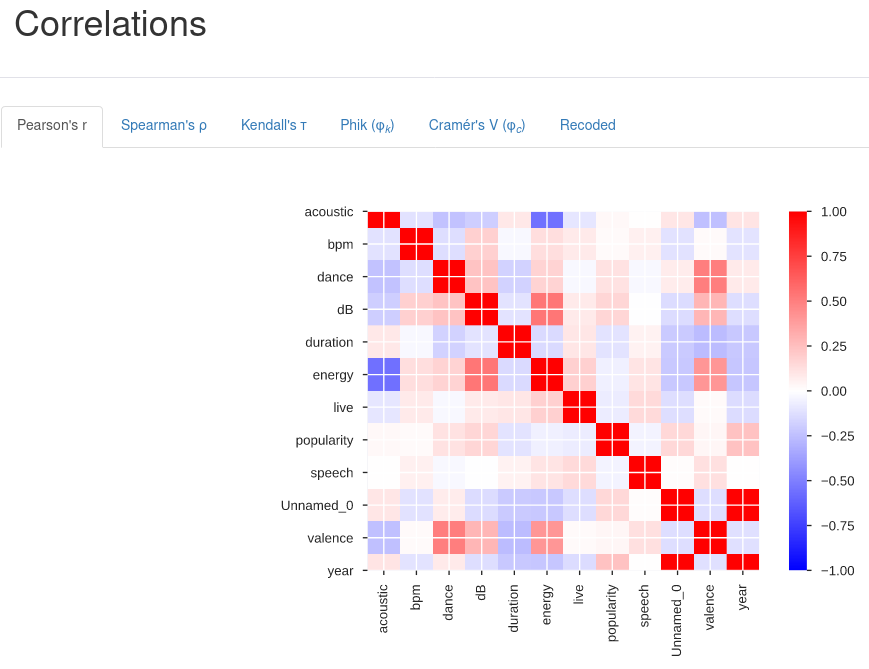
Třetí část graficky reprezentuje několik různých korelačních koeficientů mezi páry proměnných.
Část čtvrtá - Chybějící hodnoty (Missing values)
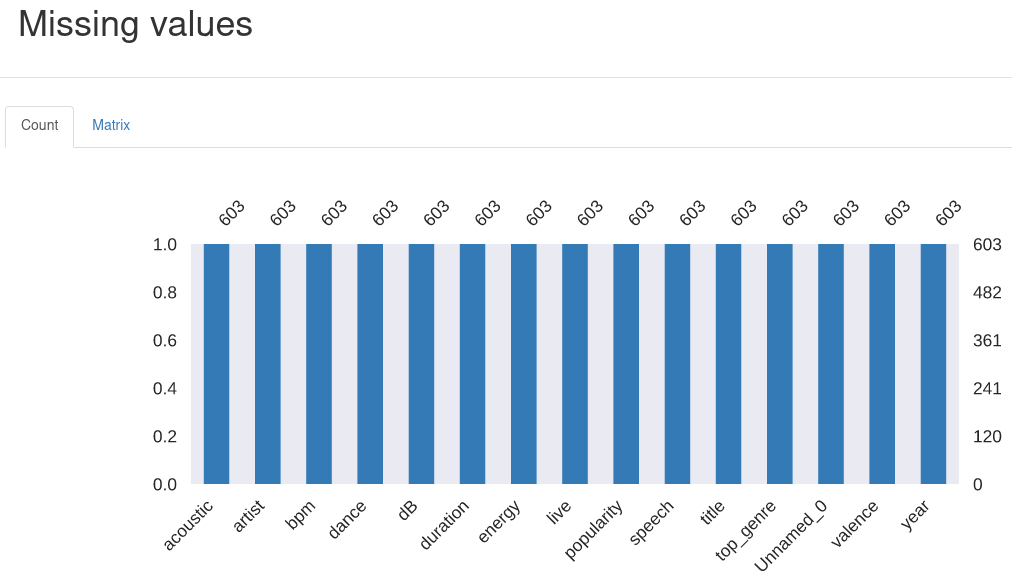
Ve čtvrté části najdeme grafické i numerické reprezentace chybějících hodnot. Zobrazení v matici nám může pomoci s detekcí jejich výskytů ve shlucích.
Část pátá - Vzorek (Sample)
Poslední část reportu obsahuje prvních deset a posledních pět řádku datasetu k nahlédnutí.
Jak využít potenciál automatických reportů
Každý analytik si samozřejmě časem vytvoří vlastní návyky a pracovní postupy, aby využil možností automatických reportů naplno, ale zároveň tak, aby se dokázal soustředit na to důležité a nenechal se unést zdánlivě překvapivými informacemi bez hlubšího manuálního zkoumání.
Častou praxí bývá vytvoření reportu na samotném začátku analýzy. Protože námi zkoušený nástroj, jak už jeho název napovídá, používá na pozadí Pandas, dokážeme z reportu poznat, jak dobrá bude automatická detekce typů jednotlivých proměnných. Pokud se detekce na první pokus nepodaří, přichází na řadu úprava vstupních dat a nové generování reportu. Pak už je možné zkoumat vlastnosti jednotlivých proměnných a vztahů mezi nimi a provádět navazující analýzy. Osobně mám nejraději otevřený report hned vedle notebooku, kde data analyzuji, protože se kdykoli můžu podívat zpět na grafy a popisné statistiky a nemusím je získávat znovu manuálně. Ne vše je ale v reportu obsaženo, a to, co tam je, nemusí být bez chyby.
Příklady
Pokud je tato ukázka málo, obsahují stránky projektu řadu příkladů reportů z různých datasetů.
Čas na hraní
Pokud se ti Pandas profiling líbí, můžeš jej zkusit použít na vlastní data z minulých lekcí a zkoumat, zda tento automatický nástroj přišel na něco, co ty ne, resp. zda by ti nějaký jeho objev dokázal ušetřit manuální práci.