Pandas - vztahy mezi více proměnnými #
# Importy jako obvykle
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
Načteme si spojené tabulky z předchozí lekce:
movies_complete = pd.read_csv("./movies_complete.csv.gz")
movies_with_rating = pd.read_csv("./movies_with_rating.csv.gz")
Vztahy mezi dvěma proměnnými #
Když jsme studovali vlastnosti zemí světa, věnovali jsme se především jednotlivým charakteristikám zvlášť, nanejvýš jsme si udělali intuitivní obrázek z bodového grafu ("scatter plot"), kde osy x a y patřily dvěma různým vlastnostem. Nyní se vztahy mezi více proměnnými budeme zabývat podrobněji a ukážeme si i některé odvážnější vizualizace.
Poznámka: Budeme pokračovat s výše uvedenými filmovými daty (a jejich sloučenými tabulkami), a tak je třeba, abys spustil/a všechny buňky předcházející této kapitole.
Co se týče vztahů mezi proměnnými, dost záleží na tom, jakého jsou typu. Tomu se podřizují zvolené typy grafů i vhodné statistické veličiny.
Dvě číselné proměnné #
Minule jsme si ukázali, jak rychle získat přehled o vlastnostech jednotlivých numerických proměnných, tak si to zopákněme:
movies_complete.describe() # Tabulka základních statistických parametrů
movies_complete.hist(figsize=(12, 8), bins=30); # Histogram coby přibližná distribuční funkce

Nejjednodušším pohledem na dvě číselné proměnné je klasický bodový graf (.plot.scatter), který jsme si už ukazovali - hodnoty dvou proměnných tvoří hodnoty souřadnic. Pomocí něj se podíváme, jaký je vztah mezi počtem hodnotitelů a průměrným hodnocením na IMDb. Očekáváme, že na špatné filmy se "nikdo nedívá" (a málokdo je hodnotí), v čemž nám následující graf dává za pravdu:
movies_complete.plot.scatter(
x="imdb_rating",
y="imdb_votes",
c="black",
figsize=(7, 7),
logy=True
);

💡 Podobnou službu udělá i funkce seabornu scatterplot, jen neumí logaritmické měřítko sama o sobě.
Už při několika stovkách filmů nám ale začínají jednotlivé body splývat. Stejný graf pro všechny ohodnocené filmy (~200 000) bude vypadat už naprosto nepřehledně:
movies_with_rating.plot.scatter(
x="imdb_rating",
y="imdb_votes",
c="black",
figsize=(7, 7),
logy=True,
ylim=(10, 1e7)
);

Pro takové množství zřejmě bude vhodnější nějakým způsobem reflektovat spíš souhrnnou hustotu bodů než jednotlivé body jako takové. První možností je udělat body dostatečně "průhledné" (pomocí argumentu alpha) a velké (argument s), aby splývaly a výraznější barva odpovídala více bodům v témže okolí:
ax = movies_with_rating.plot.scatter(
x="imdb_rating",
y="imdb_votes",
c="black",
figsize=(7, 7),
s=50, # Velikost na "rozprostření"
logy=True,
alpha=0.002, # > 99% průhlednost
lw=0 , # bez okrajů
ylim=(10, 1e7)
)

Otázka (bez známé správné odpovědi): Proč je nespojitost v hodnocení cca u sta hodnotících?
Úkol: zkus vytvořit graf zobrazující vztah mezi hodnocením filmu a počtem hlasů na Rotten Tomatoes (tabulka rotten_tomatoes).
- Velikost grafu nastav dle uvážení.
- Barva bodů oranžová, body nastav bez okraje.
- Průsvitnost bodů
0.5.
Jak je možné tento graf interpretovat? Existuje vztah mezi hodnocením filmu (kolik % kritiků hodnotí film pozitivně) a počtem hlasů?
Jinou (a lepší) možností je "spočítat" dvourozměrný histogram, který místo binů "od-do" nabízí obdélníkové chlívečky ve dvou dimenzích. Poté ho lze vizualizovat pomocí teplotní mapy (heatmap) - každý obdélník se vybarví tím intenzivnější barvou, čím více hodnot do něj "spadlo". pandas ani seaborn tuto možnost jednoduše nenabízejí, ale matplotlib nabízí užitečnou funkci hist2d. Všimni si, že předáváme řady jako takové, nikoliv jejich názvy!
Při kreslení rovnou nastavíme dva klíčové argumenty:
range: obsahuje dvojice mezí v jednotlivých dimenzích (nadbytek závorek je tuple tuplů).cmap: barevná paleta použitá pro vyjádření hodnot, seznam možností jde nalézt v dokumentaci.
Poznámka: Není úplně jednoduché pracovat s histogramy v logaritmické škále, a proto si vybereme jinou dvojici proměnných (hodnocení na IMDb a rotten tomatoes):
plt.hist2d(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
range=((6.85, 9.05), (79.5, 101.5)),
bins=(11, 11),
cmap="Greens"
) # -> (data, hranice v první ose, hranice v druhé ose, objekt grafu)

Čím tmavší zelená, tím více filmů je v daném rozsahu.
Následující obrázek intuitivně vyjadřuje, jak body do chlívečků padají (vlevo trochu zamíchané body, vpravo spočítané obsahy chlívečků):
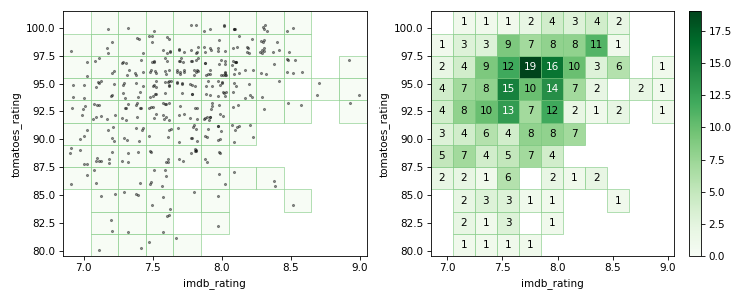
Kód (velmi volitelný) k vytvoření obrázku je v bonusovém materiálu
Úkol: Vytvoř graf z předcházejícího úkolu (vztah mezi hodnocením filmu a počtem hlasů na Rotten Tomatoes – tabulka rotten_tomatoes) ve formě dvourozměrného histogramu.
- Rozpětí hodnot pro hodnocení nastav od 70 do 100, rozpětí pro počet hlasů od 0 do 450.
- Vytvoř 6 binů pro hodnocení a 9 binů pro počet hlasů.
- Barvu grafu zvol oranžovou.
Biny nemusí být jenom pravoúhlé, ale pokud chceme poněkud méně diskriminovat různé směry, můžou se hodit biny šestiúhelníkové, které vykreslíš metodou .plot.hexbin:
movies_complete.plot.hexbin(
x="imdb_rating",
y="tomatoes_rating",
xlim=(7, 9),
ylim=(70, 100),
gridsize=40
)

Úkol: Také si zkus vytvořit graf pro hodnocení filmu a počet hlasů na Rotten Tomatoes se šestiúhelníkovými biny.
- Rozpětí hodnot na ose s hodnocením od 70 do 100.
- Počet šestiúhelníků
(25, 5), jestli je hodnocení na ose x,(5, 25)jestli je na ose y. - Barva grafu oranžová.
Který tvar binů se ti líbí víc?
Jinou možností, výpočetně náročnější, je odhadnout hustotu pravděpodobnosti výskytu filmů s danými souřadnicemi obou hodnocení. K tomu slouží tzv. jádrový odhad hustoty (kernel density estimate). Je to vlastně trochu sofistikovanější podoba splývání bodů, které jsme předvedli výše - kolem každého bodu se uvažuje pravěpodobnostní jádro, neboli kernel (typicky gaussovský), a výsledná pravděpodobnost je rovná součtu kernelů v daném místě souřadnicové soustavy.
V seabornu k tomu slouží funkce kdeplot - v jednorozměrném případě kreslí křivku, v dvourozměrném umí vykreslit buď "vrstevnice", nebo plochy různě intenzivní barvou podle spočítané hustoty pravděpodobnosti.
ax = sns.kdeplot(
x=movies_complete["imdb_rating"],
y=movies_complete["tomatoes_rating"],
n_levels=15, # Počet úrovní intenzity
fill=True, # Nechceme jen "vrstevnice", ale barevnou výplň
bw_method=.06 # Magický faktor pro míru "rozpití"
)
# Ještě si pomocí matplotlibu upravíme rozsahy os
ax.set_xlim(7, 9)
ax.set_ylim(70, 100);

Úkol: Na datech pro hodnocení filmu a počet hlasů na Rotten Tomatoes vytvořme také graf s jádrovým odhadem hustoty (kde).
- Rozpětí hodnot pro hodnocení filmu opět od 70 do 100.
- Počet úrovní intenzity 10.
- Graf bude mít barevnou výplň, ne jenom vrstevnice.
- Barva grafu oranžová.
Funkce seabornu zvaná jointplot umí velice elegantně vytvořit kombinovaný graf obsahující:
sdružené rozdělení v podobě čtvercového grafu některého z výše uvedených typů (jeho jméno přijde do argumentu
kind) pro vztah obou proměnných.marginální rozdělení v obou proměnných nezávisle (malé histográmky nebo jádrové odhady hustoty po stranách)
g = sns.jointplot(
data = movies_complete,
x = "imdb_rating",
y = "tomatoes_rating",
kind="scatter",
color="#4CB391",
xlim=(6, 9),
ylim=(70, 100),
alpha=.5
);

sns.jointplot(
data = movies_complete,
x = "imdb_rating",
y = "tomatoes_rating",
kind="kde",
color="#4CB391",
n_levels=15,
fill=True,
xlim=(7, 9),
ylim=(70, 100),
joint_kws = {"bw_method": .1}
);

Úkol: Na závěr ještě zkus vytvořit kombinovaný graf jointplot. Jako podkladová data opět využij hodnocení filmu a počet hlasů na Rotten Tomatoes.
- Druh grafu nastav
kdeneboscatter. - Barva grafu oranžová.
- Rozpětí hodnot pro hodnocení opět od 70 do 100.
- 10 úrovní intenzity pro
kdenebo průsvitnost 0.5 proscatter.
Který z prezentovaných grafů se ti líbí nejvíc? Proč?
Korelace (a nikoliv kauzalita) #
Máme-li dvě proměnné, obvykle nás zajímá, jak spolu souvisejí. Jestli ze změny jedné můžeme usuzovat na změnu druhé a naopak. V tomto smyslu rozlišuje dva základní úrovně vztahu:
Korelace mezi dvěma proměnnými znamená, že pokud se jedna z nich mění, mění se nějakým způsobem i druhá, a to v míře, kterou dokážeme alespoň částečně odhadnout. Není řečeno (obvykle to ani nejde), jestli jde o vztah příčinný (jedním, nebo druhým směrem), nebo jestli jsou třeba obě proměnné jen závislé na nějakém třetím faktoru.
Kauzalita naproti tomu znamená, že jedna proměnná je opravdu závislá na druhé, a tedy že cílenou změnou první můžeme přivodit změnu druhé.
Statistickými metodami je velice snadné prokázat korelaci, naopak je velice obtížné až nemožné ze samotných čísel vykoukat kauzalitu - to většinou vyžaduje hlubší znalost kontextu a cílené experimentování, nikoliv jen pozorování.
My si můžeme říct, jak spolu souvisí (jaká je korelace mezi nimi) hodnocení na IMDb a Rotten Tomatoes, ale těžko z čísel vyčteme, jestli se navzájem ovlivňují (aniž bychom se ptali hlasujících, na základě čeho se rozhodovali). Nejspíš selským rozumem dojdeme k tomu, že z hlediska kauzality jsou obě hodnocení nezávislá a že za případnou korelaci může spíše třetí faktor, tj. "jak se film povedl".
Korelační koeficient #
Ve světě statistiky míru korelace obvykle vyjadřujeme pomocí korelačního koeficientu. To je bezrozměrné číslo od -1 do 1, přičemž 0 znamená naprostou nezávislost, 1 značí, že jakákoliv změna v jedné veličině je provázena stejně významnou změnou ve veličině druhé, -1 pak značí změnu stejně významnou, ale v opačném směru.
Existuje několik metod výpočtu korelačního koeficientu. Pandas umí v základu tři, z nich si ukážeme jen ten výchozí, Pearsonův, který je ideální pro odhalení lineárních vztahů.
Následující obrázek ukazuje typické hodnoty korelačního koeficientu pro různá rozdělení dvou proměnných:
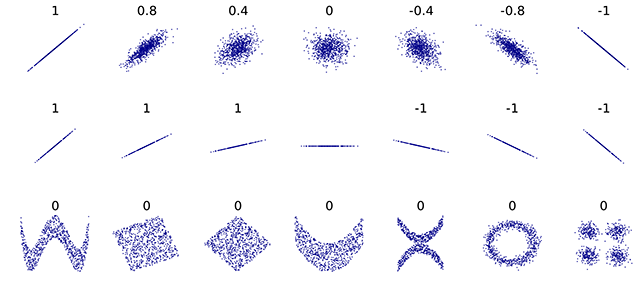
Obrázek převzat z wikipedie.
{kind=link}
Výpočet korelačního koeficientu mezi dvěma Series se v pandas provede zavoláním metody .corr:
movies_complete["imdb_rating"].corr(movies_complete["tomatoes_rating"])
Číslo 0,667 ukazuje na poměrně silný vztah - čím lepší hodnocení na jednom serveru, tím lepší hodnocení na serveru druhém.
Kompletní tabulku korelačních koeficientů mezi všemi sloupci v tabulce získáš metodou .corr na tabulce samotné:
movies_complete.corr(method="pearson", numeric_only=True) # Jsme explicitní ohledně typu koeficientu
Co je z tabulky vidět?
- každá proměnná plně koreluje sama se sebou (1,0)
- nelze spočítat korelační koeficient
is_adult, protože tento sloupec obsahuje jen jednu hodnotu - jak jsme již zmiňovali, hodně korelují hodnocení na IMDb a na Rotten Tomatoes
- čím více hlasů na IMDb, tím obvykle lepší hodnocení (kdo by se díval na špatné filmy?), vyšší celkový zisk v kinech (kdo by hodnotil, kdyby film nikdo neviděl?)
- možná překvapí silná korelace počtu hodnocení na Rotten Tomatoes a roku premiéry (je to tím, že se filmově-kritické weby množí jako houby po dešti?)
A mnoho dalšího...
Varování: Velký (kladný nebo záporný) korelační koeficient téměř vždy značí nějaký (zejména lineární či aspoň monotónní) vztah mezi proměnnými. Opačně to ovšem neplatí - korelační koeficient blízký nule může zahrnovat jak případy naprosté nezávislosti, tak situace, kdy vztah mezi proměnnými je komplexnějšího charakteru, jak je vidět v dolním řádku obrázku výše.
Dovedeno do extrému, není vůbec problém nakreslit téměř libovolně vypadající obrázek alias bodový graf, který bude mít dané souhrnné statistiky (tedy naivně pohlíženo "bude stejný"). V pěkném interaktivním článku Same Stats, Different Graphs... autoři ukazují pěkné animace plynulých přechodů mezi naprosto odlišně vyhlížejícími sadami, aniž by se změnila kterákoliv ze základních statistik včetně korelací.
Pokud chceš najednou zobrazit vztahy všech dvojic různých numerických proměnných, může se hodit funkce pairplot, která vykresli čtvercovou mřížku s histogramy na diagonále a dvourozměrnými grafy (ve výchozím nastavení bodovými) mimo diagonálu:
sns.pairplot(movies_complete, vars = ["year", "imdb_rating", "imdb_votes", "tomatoes_rating", "lifetime_gross"])

Dvě kategorické proměnné #
Protože máme kategorických proměnných v tabulkách o filmech málo, musíme si je vyrobit. A přitom se naučíme další dva triky.
První trik: Kategorická proměnná z číselné
Vezmeme rok premiéry filmu a přiřadíme mu dekádu pomocí funkce cut. Tato funkce vezme nějakou číselnou Series a hranice binů ("chlívečků", stejně jako u histogramu) a každou hodnotu označí příslušným intervalem (jeho dolní a horní hranicí):
pd.cut(
movies_with_rating["year"],
bins=range(1890, 2021, 10) # 1890, 1900, 1910, ..., 2020
)
To je přesné, ale nepříliš estetické. Takže provedeme ještě jednu úpravu - z intervalu pomocí metody apply a námi definové funkce uděláme hezké označení dekády ((1980, 1990] nahradíme řetězcem "1980s").
def interval_to_decade_name(interval):
"""Převede (1980, 1990] na 1980s apod."""
return str(interval.left)+"s"
pd.cut(
movies_with_rating["year"],
bins=range(1890, 2021, 10)
).apply(interval_to_decade_name)
💡 V pravém smyslu dekáda není kategorickou, ale ordinální proměnnou, protože má přirozené řazení, ale nic nám nebrání s ní jako s kategorickou zacházet.
Druhý trik: Kategorická proměnná ze seznamu hodnot
Sloupec genres je velice užitečný, ale protože obsahuje různé kombinace hodnot, navíc oddělených čárkou v řetězci, s ním samotným toho moc nepořídíme. Potřebujeme proto skupiny žánrů rozhodit do nezávislých řádků (každý film se nám pak v tabulce opakovat tolikrát, do kolika různých žánrů patří). K tomu použijeme metody str.split (rozděluje řetězec na seznam podle nějakého oddělovače) a explode (zkopíruje řádek pro každou jednotlivou položku seznamu v nějakém sloupci):
(movies_with_rating["genres"]
.str.split(",") # řetězec -> seznam
.explode() # zkopíruje řádky => pro každý žánr jednu kopii
)
Toto je pravověrná kategorická proměnná. Pojďme si tedy sestavit tabulku, která obsahuje obě:
decades_and_genres = (
movies_with_rating.assign(
decade = pd.cut(
movies_with_rating["year"],
bins=range(1890, 2021, 10)
).apply(interval_to_decade_name),
genres = movies_with_rating["genres"].str.split(",")
)
.rename({"genres": "genre"}, axis="columns")
.explode("genre")
)[["title", "genre", "decade", "imdb_rating", "imdb_votes"]]
decades_and_genres
U dvou kategorických proměnných nás obvykle zajímá, jak často se vyskytuje jejich kombinace - v našem případě tedy kolik filmů daného žánru bylo natočeno v které dekádě. Toto přesně dělá funkce crosstab:
decades_vs_genres = pd.crosstab(
decades_and_genres["decade"], # Co se použije jako řádky
decades_and_genres["genre"], # Co se použije jako sloupce
)
decades_vs_genres
Případně nemusíme zkoumat jenom počet, může nás zajímat i jiná agregace - v tom případě musíme uvést argumenty values (na čem se agregace bude provádět) a aggfunc (jaká agregační funkce se použije).
Zkusme tedy např. průměrné hodnocení jednotlivých žánrů v dané dekádě (že by se dokumentání filmy lepšily a horory horšily?):
decades_vs_genres_rating = pd.crosstab(
index=decades_and_genres["decade"],
columns=decades_and_genres["genre"],
values=decades_and_genres["imdb_rating"],
aggfunc="mean"
)
decades_vs_genres_rating[["Documentary", "Horror"]] # Vybereme dva zajímavé sloupce
Pokud si chceme hodnoty z .crosstab, můžeme si nakreslit teplotní mapu (podobně jako dříve u dvourozměrných histogramů) pomocí funkce heatmap:
sns.heatmap(decades_vs_genres);

Toto jednoduché zobrazení asi není příliš přehledné, proto zkusíme přidat trochu estetiky. Většinu popsaných argumentů najdeš v dokumentaci a okomentovanou přímo v kódu, širší komentář (zejména k barevné paletě) pro "jednoduchost" vynecháme:
from matplotlib.colors import LogNorm
# Vytvoříme si škálu hodnot rovnoměrnou v logaritmickém měřítku
# Tato škála se pakkterá bude mapovat
log_norm = LogNorm(
vmin=1, # Kde škála začíná
vmax=decades_vs_genres.max().max(), # Kde škála končí
)
_, ax = plt.subplots(figsize=(18,5.5)) # Vytvoříme dostatečně veliký graf
sns.heatmap(
decades_vs_genres,
ax=ax, # Kreslíme do připraveného objektu `Axes`
vmin=1, # Ignorujeme nulové hodnoty (nejdou logaritmovat!)
linewidths=1, # Oddělíme jednotlivá okénka
annot=True, # Chceme zobrazit hodnoty
fmt="d", # Zobrazíme hodnoty jako celá čísla
norm=log_norm, # Použijeme škálování
cmap="PuBu", # Vybereme si barevnou paletu
cbar=False, # Schováme barevný proužek vpravo, nepotřebujeme ho
);
ax.set_ylim(13, 0); # Obcházíme oříznutí, které je asi bug seabornu

Prakticky vzato se pak tato vizualizace nachází někde na pomezí tabulky a grafu.
Kategorická a číselná proměnná #
Když se zkoumají vztahy kategorických a numerických proměnných, koukáme se vlastně na sadu numerických proměnných, vyhodnocovaných pro každou hodnotu kategorické proměnné zvlášť. V našem případě tedy pro horory zvlášť, pro dokumenty zvlášť apod. Z výpočetního hlediska je toto téma pro shlukování a operaci groupby, kterým se detailně věnuje příští hodina. Nyní si jen ukážeme některé pěkné vizualizace.
Předtím, než začneme s použitím knihovny seaborn, musíme upravit dulicitu indexů, která nám zatím vznikla. Druhá možnost by byla vybrat subset filmů, například dokumentů.
decades_and_genres = decades_and_genres.reset_index() # seabornu vadí duplicitní index
Krabicový graf si jistě pamatuješ z minula, pomocí seabornu ho vytvoříš zavoláním funkce boxplot - jen se nekreslí krabičky pro různé proměnné, ale pro tutéž číselnou proměnnou, jen v závislosti na hodnotě proměnné kategorické:
_, ax = plt.subplots(figsize=(12, 5)) # boxplot neumí specifikovat velikost grafu
sns.boxplot(data=decades_and_genres,
x="decade",
y="imdb_rating",
hue= "decade", # obarvení grafu, aby jednotlivé dekády neměly stejnou barvu
ax=ax
) # kam se bude kreslit
ax.get_legend().set_visible(False) # smazání legendy

Vedle toho "strip plot" (funkce stripplot) znázorňuje každou hodnotu tečkou, vysázenou ve sloupci nad příslušnou kategorií (ve správné výšce, nicméně přesné horizontální umístění nenese žádnou informaci):
_, ax = plt.subplots(figsize=(12, 5)) # stripplot neumí specifikovat velikost grafu
sns.stripplot(
data=decades_and_genres, # seabornu vadí duplicitní index
x="decade",
y="imdb_rating",
s=1,
ax=ax,
hue= "decade"
) # kam se bude kreslit
ax.get_legend().set_visible(False)

Velice podobnou roli jako krabicový graf hraje houslový ~plot~ graf, který místo čtverců nabízí miniaturní křivku hustoty pravděpodobnosti (resp. jádrový odhad). Vykreslíš ho funkcí violinplot:
_, ax = plt.subplots(figsize=(12, 5)) # violinplot neumí specifikovat velikost grafu
sns.violinplot(
data=decades_and_genres,
x="decade",
y="imdb_rating",
ax=ax,
hue= "decade"
) # kam se bude kreslit
ax.get_legend().set_visible(False)

Vztahy mezi více proměnnými #
Pokud si tyto materiály nečteš na holografickém displeji, jsi při zobrazování dat omezen/a na dva rozměry. Můžeš si prohlížet dvourozměrné tabulky, kreslit dvourozměrné grafy. Interaktivní knihovny pro vizualizaci dat ti pomocí posuvníků umožní prohlížet si různé jednorozměrné nebo dvourozměrné řezy vícerozměrných vztahů.
Matplotlib i plotly umějí vykreslovat 3D grafy, tak se tím můžeš inspirovat, ale není to moc praktické.
💡 V jistém smyslu jsme si už předminule ukázali, jak třetí a čtvrtý rozměr do dvourozměrného grafu přeci jen propašovat - pomocí barvy a velikosti symbolu. Ne vždy je to snadné a přehledné, ale v některých situacích je to dobrá volba.
3D grafy (nepovinné až zbytečné) #
Pokud chceš v matplotlibu kreslit trojrozměrné grafy, musíš si síť souřadnic vytvořit specifickým způsobem.
from mpl_toolkits.mplot3d import Axes3D # Import, bez kterého nebude následující fungovat
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')

Potom už se zbylá volání budou chovat podobně jako ve dvou rozměrech:
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
movies_complete["lifetime_gross"])
ax.set_xlabel("IMDb rating")
ax.set_ylabel("Rotten Tomatoes rating")
ax.set_zlabel("Gross (total)");

Graf je to poněkud statický a třetí rozměr nám uniká (a ani 3D brýle nepomohou).
Pokud kreslíš grafy mimo jupyter notebook a máš například nainstalovaný framework Qt, můžeš si grafy z matplotlibu prohlížet i interaktivně, což v tomto případě je velice užitečné.
Naproti tomu uvnitř notebooku v notebooku je výrazně efektivnější použít plotly (resp. plotly.express):
# Toto nemusí fungovat všem, můj prohlížeč si stěžuje na chybějící WebGL
import plotly.express as px
fig = px.scatter_3d(movies_complete, x="imdb_rating", y="tomatoes_rating", z="lifetime_gross", hover_name="title")
fig.show()
Bonusový materiál #
Obrázek ilustrující plnění 2D histogramu:
import numpy as np
import physt
np.random.seed(42)
limits=[(6.85, 9.05), (79.5, 101.5)]
bins=[11, 11]
# Ve phystu vytvoříme objekt 2D histogramu
h2 = physt.h2(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
bins=bins,
range=limits,
)
# Chceme ne jeden, ale dva grafy vedle sebe!!!
fig, ax = plt.subplots(1, 2, figsize=(10,4))
##### levý graf
# Vykreslíme si histogram, ale schováme ho
h2.plot(
cmap="Greens", # Paleta, kterou použijeme v pravém grafu
cmap_min=0,
cmap_max=1e9, # Zajistíme si, že všechy biny budou mít první barvu palety
show_zero=False, # Nenakreslí se nám prázdné biny
ax=ax[0], # Nakreslíme do levého podgrafu
show_colorbar=False, # Nepotřebujeme legendu k paletě
zorder=-1, # Schováme za následující scatterplot
#alpha=0,
)
# Scatterplot překreslený přes "histogram" s body mírně rozházenými, aby se daly spočítat
ax[0].scatter(
movies_complete["imdb_rating"] + np.random.uniform(-.03, .03, len(movies_complete["imdb_rating"])),
movies_complete["tomatoes_rating"]+ np.random.uniform(-.3, .3, len(movies_complete["imdb_rating"])),
s=4,
color="black",
alpha=0.4,
)
ax[0].set_xticks([7.0, 7.5, 8.0, 8.5, 9.0])
##### Pravý graf ukazuje, kolik bodů spadlo do kterého obdélníku
# Tady už použijeme vykreslování histogramů
h2.plot(
show_values=True, # Chceme v binech zobrazit čísla
cmap="Greens",
show_zero=False,
ax=ax[1], # Kreslíme do pravéoho podgrafu
show_colorbar=True # Chceme ukázat legendu k paletě
)
# Uložíme obrázek s dostatečným rozlišením
fig.savefig("static/plneni_2d_hist.png", dpi=75)
