Pandas - spojování tabulek a vztahy mezi více proměnnými
Tato lekce se nese ve znamení mnohosti a propojování - naučíš se:
- pracovat s více tabulkami najednou
- nacházet spojitosti mezi dvěma (a více) proměnnými
Při tom společně projdeme (ne poprvé a ne naposledy) čištění reálných datových sad.
# Importy jako obvykle
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Spojování tabulek
V lekci, kde jsme zpracovávali data o počasí, jsme ti ukázali, že je pomocí funkce concat možné slepit dohromady několik objektů DataFrame či Series, pokud mají "kompatibilní" index. Nyní se na problematiku podíváme trochu blíže a ukážeme si, jak spojovat tabulky na základě různých sloupců, a co dělat, když řádky z jedné tabulky nepasují přesně na tabulku druhou.
Obecně pro spojování pandas nabízí čtyři funkce / metody, z nichž každá má svoje typické využití (možnostmi se ovšem překrývají):
concatje univerzální funkce pro slepování dvou či více tabulek / sloupců - pod sebe, vedle sebe, s přihlédnutím k indexům i bez něj.append(metoda) je jednodušší alternativouconcat, pokud jen chceš do nějaké tabulky přidat pár řádků.mergeje univerzální funkce pro spojování tabulek na základě vazby mezi indexy nebo sloupci.join(metoda) zjednodušuje práci, když chceš spojit dvě tabulky na základě indexu.
Detailní rozbor toho, co která umí, najdeš v dokumentaci. My si je také postupně ukážeme.
Jednoduché skládání
a = pd.Series(["jedna", "dvě", "tři"])
b = pd.Series(["čtyři", "pět", "šest"])
a.append(b)
💡 Vidíš, že se index opakuje? Vytvořili jsme dvě Series, u kterých jsme index neřešili. Jenže pandas na rozdíl od nás ano, a tak poslušně oba indexy spojil, i za cenu duplicitních hodnot. Za cenu použití dodatečného argumentu ignore_index=True se tomu lze vyhnout, což si ukážeme na příklady spojování dvou tabulek o stejných sloupcích:
df1 = pd.DataFrame({
"levy": [1, 2],
"pravy": [3, 4]
})
df2 = pd.DataFrame({
"levy": [25, 26],
"pravy": [47, 48]
})
df1.append(df2, ignore_index=True)
Totéž s použitím concat:
pd.concat([a, b])
pd.concat([a, a, a, a, a], ignore_index=True)
Vedle sebe
Když chceme "lepit" doprava (třeba deset Series), stačí přidat nám dobře známý argument axis:
pd.concat([a, a, a, a, a], axis="columns")
Příklad: Jak co nejrychleji "nakreslit prázdnou šachovnici" (obě slova jsou v uvozovkách)?
sachy = pd.concat(
[
pd.concat(
[pd.DataFrame([["⬜", "⬛"], ["⬛", "⬜"]])] * 4,
axis=1)
] * 4
)
sachy.index = list(range(8, 0, -1))
sachy.columns = list("ABCDEFGH")
sachy
Spojování různorodých tabulek
🎦 Pro spojování heterogenních dat (v datové hantýrce "joinování") sáhneme po trochu komplexnějších filmových datech...
Data jsou docela veliká. Jsou tak veliká, že ti je nemůžeme naservírovat na stříbrném podnose (leda bys sebou takový podnos měl/a a na něm ležela flashka - na tu ti je můžeme nahrát). Nabízí se dvě možnosti, jak je můžeš získat:
Alternativa 1. Stáhni si manuálně do aktuálního adresáře následující soubory:
- https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/title.basics.tsv.gz
- https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/title.ratings.tsv.gz
- https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/rotten_tomatoes_top_movies_2019-01-15.csv
- https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/boxoffice_march_2019.csv.gz
Alternativa 2: Pusť si (ideálně ještě doma, před hodinou) následující kód, který stáhne všechny potřebné soubory - navíc to učiní pouze jednou, opětovné volání už nic dalšího nestahuje.
# Nutné importy
import os
import requests
# Seznam souborů (viz níže)
zdroje = [
"https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/title.basics.tsv.gz",
"https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/title.ratings.tsv.gz",
"https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/rotten_tomatoes_top_movies_2019-01-15.csv",
"https://github.com/coobas/pycon-cz-2019-workshop/raw/master/data/boxoffice_march_2019.csv.gz"
]
for zdroj in zdroje:
# Pouze poslední část cesty adresy datového zdroje je jeho jméno
jmeno = zdroj.rsplit("/")[-1]
if not os.path.exists(jmeno):
print(f"Soubor {jmeno} ještě není stažen, jdeme na to...")
response = requests.get(zdroj)
with open(jmeno, "wb") as out:
out.write(response.content)
print(f"Soubor {jmeno} úspěšně stažen.")
else:
print(f"Soubor {jmeno} už byl stažen, použijeme místní kopii.")
print("Všechny soubory jsou staženy.")
Hotovo? :-)
Máme staženo několik souborů, načteme si je (zatím hrubě, "raw") - s přihlédnutím k tomu, že první dva nejsou v pravém slova smyslu "comma-separated", ale používají k oddělení hodnot tabulátor (tady pomůže argument sep). Také zohledníme, že v nich řetězec "\N" představuje chybějící hodnoty (pomůže argument na_values):
imdb_titles_raw = pd.read_csv("title.basics.tsv.gz", sep="\t", na_values="\\N")
imdb_ratings_raw = pd.read_csv("title.ratings.tsv.gz", sep="\t", na_values="\\N")
boxoffice_raw = pd.read_csv("boxoffice_march_2019.csv.gz")
rotten_tomatoes_raw = pd.read_csv("rotten_tomatoes_top_movies_2019-01-15.csv")
Co který soubor obsahuje?
První dva soubory obsahují volně dostupná (byť "jen" pro nekomerční použití) data o filmech z IMDb (Internet Movie Database). My jsme si zvolili obecné informace a uživatelská (číselná) hodnocení. Detailní popis souborů, stejně jako odkazy na další soubory, najdeš na https://www.imdb.com/interfaces/. Z důvodů paměťové náročnosti jsme datovou sadu ořezali o epizody seriálů, protože nás nebudou zajímat a s trochu štěstí přežijeme i na počítačích s menší operační pamětí.
Soubor
boxoffice_march_2019.csv.gzobsahuje informace o výdělcích jednotlivých filmů. Pochází z ukázkového datasetu pro soutěž "TMDB Box Office Prediction" na serveru Kaggle: https://www.kaggle.com/c/tmdb-box-office-prediction/dataSoubor
rotten_tomatoes_top_movies_2019-01-15.csvobsahuje procentuální hodnocení filmů ze serveru Rotten Tomatoes, které se počítá jako podíl pozitivních hodnoceních od filmových kritiku (je to tedy jiný princip než na IMDb). Staženo z: https://data.world/prasert/rotten-tomatoes-top-movies-by-genre
Pojďme se podívat na nedostatky těchto souborů a postupně je skládat dohromady. Zajímalo by nás (a snad i tebe!), jak souvisí hodnocení s komerční úspěšností filmu, jak se liší hodnocení rotten tomatoes od těch na IMDb.
imdb_titles_raw
# Kolik tabulka zabírá megabajtů paměti? (1 MB = 2**20 bajtů)
imdb_titles_raw.memory_usage(deep=True).sum() / 2**20
Jistě budeme chtít převést sloupce na správné typy. Jaké jsou v základu?
imdb_titles_raw.dtypes
Na co budeme převádět?
tconstje řetězec, který posléze použijeme jako index, protože představuje unikátní identifikátor v databázi IMDb.titleType:
imdb_titles_raw["titleType"].value_counts()
Jen devět různých hodnot ve skoro 2 milionech řádků? To je ideální kandidát na převedení na typ "category".
primaryTitleaoriginalTitlevypadají jako obyčejné řetězce (pokud možno anglický a pokud možno původní název)isAdulturčuje, zda se jedná o dílo pro dospělé. Tento sloupec bychom nejspíše měli převést nabool.
imdb_titles_raw["isAdult"].value_counts()
startYearaendYearobsahují roky, t.j. celá čísla, ovšem kvůli chybějícím hodnotám je pro ně zvolen typfloat64. Vpandasraději zvolíme tzv. "nullable integer", který se zapisuje s velkým "I". Když nevíš, jaký podtyp konkrétně, sáhni poInt64.- totéž platí pro
runtimeMinutes.
imdb_titles_raw[["startYear", "endYear", "runtimeMinutes"]].max()
Mimochodem všimli jste si, že máme díla z budoucnosti (rok 2115)?
imdb_titles_raw["startYear"].plot.hist()
imdb_titles_raw.query("startYear > 2019")["startYear"].value_counts().sort_index()

Takhle nějak by přetypování mohlo vypadat:
(
imdb_titles_raw
.assign(
titleType=imdb_titles_raw["titleType"].astype("category"),
startYear=imdb_titles_raw["startYear"].astype("Int64"),
endYear=imdb_titles_raw["endYear"].astype("Int64"),
isAdult=imdb_titles_raw["isAdult"].astype(bool),
runtimeMinutes=imdb_titles_raw["runtimeMinutes"].astype("Int64")
)
).dtypes
Takhle už by to mohlo být. Jen si ještě:
- pro přehlednost přejmenujeme některé sloupce (pomocí metody
rename) - použijeme
tconstjako index
A tabulka imdb_titles bude připravená k použití!
imdb_titles = (
imdb_titles_raw
.assign(
titleType=imdb_titles_raw["titleType"].astype("category"),
startYear=imdb_titles_raw["startYear"].astype("Int64"),
endYear=imdb_titles_raw["endYear"].astype("Int64"),
isAdult=imdb_titles_raw["isAdult"].astype(bool),
runtimeMinutes=imdb_titles_raw["runtimeMinutes"].astype("Int64")
)
.rename({
"primaryTitle": "title",
"originalTitle": "original_title",
"titleType": "title_type",
"runtimeMinutes": "length",
"startYear": "start_year",
"endYear": "end_year",
"isAdult": "is_adult",
}, axis="columns")
.set_index("tconst")
)
imdb_titles
# Kolik tabulka zabírá megabajtů paměti?
imdb_titles.memory_usage(deep=True).sum() / 2**20 # O chlup méně, zase tolik jsme si ale nepomohli.
Připravíme si ještě speciální tabulku jenom pro filmy, protože další datové sady se zabývají jenom jimi.
U této tabulky navíc vyhodíme zbytečné sloupce title_type, end_year a přejmenujeme start_year prostě na year:
movies = (
imdb_titles
.query("title_type == 'movie'")
.drop(["title_type", "end_year"], axis="columns")
.rename({"start_year": "year"}, axis="columns")
)
movies
print(movies.shape)
print(movies.dtypes)
Nyní se podíváme na zoubek hodnocením z IMDb, na tabulky imdb_ratings_raw:
imdb_ratings_raw
imdb_ratings_raw.dtypes
To by vlastně skoro mohlo být!
Tak jen nastavíme index (opět tconst) a přejmenujeme sloupce:
ratings = (imdb_ratings_raw
.rename({
"averageRating": "imdb_rating",
"numVotes": "imdb_votes"
}, axis="columns")
.set_index("tconst")
)
ratings
První join
Máme připravené dvě krásné tabulky, které sdílejí stejný index, a můžeme vesele spojovat. Protože pomocí join, merge a concat lze volbou vhodných parametrů dosáhnout identického výsledku (což je jedním z nešvarů knihovny pandas), ukážeme si všechny tři alternativy podle subjektivního pořadí vhodnosti. A úplně nakonec si ukážeme, jak by to šlo, ale rozhodně by se dělat nemělo!
movies.join(ratings)
K tabulce se nenápadně přidaly dva sloupce z tabulky ratings, a to takovým způsobem, že se porovnaly hodnoty indexu (tedy tconst) a spárovaly se ty části řádku, kde se tento index shoduje.
💡 Uvědom si (ačkoliv z volání funkcí v pandas to není úplně zřejmé), že se tady děje něco fundamentálně odlišného od "nalepení doprava" - tabulky tu nejsou chápány jako čtverečky, které jde skládat jako lego, nýbrž jako zdroj údajů o jednotlivých objektech, které je potřeba spojit sémanticky.
Jak ale vidíš, tabulka obsahuje spoustu řádků, kde ve sloupcích s hodnocením chybí hodnoty (respektive nachází se NaN). To vychází ze způsobu, jakým metoda join ve výchozím nastavení "joinuje" - použije všechny řádky z levé tabulky bez ohledu na to, jestli jim odpovídá nějaký protějšek v tabulce pravé. Naštěstí lze pomocí argumentu how specifikovat i jiné způsoby spojování:
left(výchozí pro metodujoin) - vezmou se všechny prvky z levé tabulky a jim odpovídající prvky z pravé tabulky (kde nejsou, doplní seNaN)right- vezmou se všechny prvky z pravé tabulky a jim odpovídající prvky z levé tabulky (kde nejsou, doplní seNaN)inner(výchozí pro funkcimerge) - vezmou se jen ty prvky, které jsou v levé i pravé tabulce.outer(výchozí pro funkciconcat) - vezmou se všechny prvky, z levé i pravé tabulky, kde něco chybí, doplní seNaN.
V podobě Vennově diagramu, kde kruhy představují množiny řádků v obou zdrojových tabulkách a modrou barvou jsou zvýrazněny řádky v tabulce cílové:

Obrázek adaptován z https://upload.wikimedia.org/wikipedia/commons/9/9d/SQL_Joins.svg (autor: Arbeck)
{kind=link}
💡 Až budeme probírat databáze, tyto čtyři typu joinů se nám znovu vynoří.
Následující výpis ukáže, kolik řádků bychom dostali při použití různých hodnot how:
for how in ["left", "right", "inner", "outer"]:
print(f"movies.join(ratings, how=\"{how}\"):", movies.join(ratings, how=how).shape[0], "řádků.")
A teď tedy ty čtyři alternativy:
# Alternativa 1 (preferovaná)
movies_with_rating = movies.join(ratings, how="inner")
movies_with_rating
# Alternativa 2 (taky dobrá)
pd.merge(movies, ratings, left_index=True, right_index=True)
# Alternativa 3 (méně "sémantická")
pd.concat([movies, ratings], axis="columns", join="inner")
# Alternativa 4 (ok, tahle JE špatná)!
# Omezíme se na začátek tabulky, nebo nám dojde paměť
# `append` vkládá jen pod sebe, tak si tabulky otočíme!
df1 = movies[:6].T
df2 = ratings.T
(
df1
.append(df2, sort=False) # Sloučíme "řádky"
.T # Otočíme zpátky
.dropna( # Vyhodíme nepasující (emulace "inner")
subset=["title", "imdb_rating"],
)
)
# Začátek tabulky sedí!
Zkusme si zreprodukovat pořadí 250 nejlepších filmů z IMDb (viz https://www.imdb.com/chart/top/?ref_=nv_mv_250):
# Ty nejlepší (do června 2019)
(movies_with_rating
.query("imdb_votes > 25000") # Berou se jen filmy s více než 25000 hlasy
.sort_values("imdb_rating", ascending=False) # IMDb tu použivá i váhu jednotlivých hlasů (kterou neznáme)
.reset_index(drop=True)
).iloc[:250]
Do výčtu se nám dostaly filmy, které hranici hlasů nepřekračují o moc. Máme důvodné podezření, že toto kritérium dávno změnili. S požadovanými 250 000 hlasy se už blížíme:
(movies_with_rating
.query("imdb_votes > 250000")
.sort_values("imdb_rating", ascending=False)
.reset_index(drop=True)
).iloc[:250]
Druhý join
Co tabulka s výdělky (boxoffice_raw)?
boxoffice_raw
boxoffice_raw.dtypes
S tím bychom v podstatně mohli být spokojení, jen přejmenujeme rank, abychom při joinování věděli, odkud daný sloupec pochází.
boxoffice = (boxoffice_raw
.rename({
"rank": "boxoffice_rank"
}, axis="columns")
)
A zkusíme joinovat. V tomto případě se nemůžeme opřít o index (boxoffice pochází z jiného zdroje a o nějakém ID filmu z IMDb nemá ani tuchy), ale explicitně specifikujeme, který sloupec (či sloupce) se musí shodovat - na to slouží argument on:
pd.merge(
movies_with_rating,
boxoffice,
suffixes=[" (imdb)", " (boxoffice)"],
on="title"
).query("title == 'Pinocchio'") # "Jeden" ukázkový film
Jejda, to jsme asi nechtěli. Existuje spousta různých Pinocchiů a ke každému z nich se připojili vždy oba snímky tohoto jména z boxoffice. Z toho vyplývá poučení, že při joinování je dobré se zamyslet nad jedinečností hodnot ve sloupci, který používáme jako klíč. Jméno filmu takové očividně není.
V našem konkrétním případě jsme si problému všimli sami, ale pokud bude duplikátní klíč utopen někde v milionech hodnot, rádi bychom, aby to počítač poznal za nás. K tomu slouží argument validate - podle toho, jaký vztah mezi tabulkami očekáš, jsou přípustné hodnoty "one_to_one", "one_to_many", "many_to_one" nebo "many_to_many":
pd.merge(
movies_with_rating,
boxoffice,
on="title",
suffixes=[" (imdb)", " (boxoffice)"],
# validate="one_to_one" # Odkomentuj a vyskočí chyba!
)
Řešení je jednoduché - budeme joinovat přes dva různé sloupce (argument on to unese ;-)). Při té příležitosti navíc zjišťujeme, že nedává smysl spojovat filmy, které rok vůbec uvedený nemají, a proto je vyhodíme:
(
pd.merge(
movies_with_rating.dropna(subset=["year"]), # Vyhoď všechny řádky bez roku
boxoffice,
on=["title", "year"],
validate="many_to_one", # movies_with_rating pořád nejsou unikátní!
)
).query("title == 'Playback'")
Pořád nejsou unikátní! Co s tím?
Hypotéza: Vstupujeme na nebezpečnou půdu a zkusíme spekulovat, že informace o ziscích budeme mít nejspíš jen o nejpopulárnějších filmech. Možná máme pravdu, možná ne a nejspíš nějakou drobnou nepřesnost zaneseme, ale dobrat se tady skutečné pravdy je "drahé" (a možná i skutečně drahé), z nabízených datových sad to věrohodně možné není.
Abychom se co nejvíc přiblížili realitě, z každé opakující se dvojice (název, rok) vybereme film s nejvyšším imdb_votes. Nejdříve si pomocí sort_values srovnáme všechny filmy a pak zavoláme drop_duplicates(..., keep="first"), což nám ponechá vždy jen jeden z řady duplikátů:
movies_with_rating_and_boxoffice = (
pd.merge(
movies_with_rating
.dropna(subset=["year"])
.sort_values("imdb_votes", ascending=False)
.drop_duplicates(
subset=["title", "year"],
keep="first"
),
boxoffice,
on=["title", "year"],
validate="one_to_one",
)
)
movies_with_rating_and_boxoffice
# To už by šlo!
movies_with_rating_and_boxoffice.query("title == 'Playback'")
Úkol: Seřaď filmy podle toho, kolik vydělaly (nabízí se hned dvě možnosti).
Otázka: Které filmy nám vypadly a proč?
Třetí join
rotten_tomatoes_raw
rotten_tomatoes_raw["Title"].value_counts()
A zase duplicity, některé názvy se nám opakují :-(
Otázka: Dokážeš zjistit proč? Nápověda: podívej se na nějaký konkrétní film.
Naštěstí už víme, jak na to - použijeme metodu drop_duplicates, tentokrát přes sloupec "Title". (Poznámka: druhou možností by bylo sloučit všechny různé žánry daného filmu do jedné buňky).
rotten_tomatoes_nodup = (
rotten_tomatoes_raw
.drop_duplicates(
subset="Title",
keep="first" # Vybereme první výskyt, lze i "last" (anebo False => vyhodit všechny)
)
.drop("Genres", axis="columns") # Informační hodnotu jsme už ztratili
.drop("Rank", axis="columns") # Mělo smysl jen v rámci žánru
)
rotten_tomatoes_nodup
# Ready to merge?
pd.merge(imdb_titles, rotten_tomatoes_nodup, left_on="title", right_on="Title")
0 řádků!
Dosud jsme manipulovali s řádky a sloupci jako celky, nicméně teď musíme zasahovat přímo do hodnot v buňkách. I to se při slučování dat z různých zdrojů nezřídka stává. Stojíme před úkolem převést řetězce typu "Black Panther (2018)" na dvě hodnoty: název "Black Panther" a rok 2018 (jeden sloupec na dva).
Naštěstí si ty sloupce umíme jednoduše vyrobit pomocí řetězcové metody .str.slice, která z každého řetězce vyřízne nějakou jeho část (a zase pracuje na celém sloupci - výsledkem bude nový sloupec s funkcí aplikovanou na každou z hodnot). Budeme věřit, že předposlední čtyři znaky představují rok a zbytek, až na nějaké ty závorky, tvoří skutečný název:
rotten_tomatoes_beta = (rotten_tomatoes_nodup
.assign(
title=rotten_tomatoes_nodup["Title"].str.slice(0, -7),
year=rotten_tomatoes_nodup["Title"].str.slice(-5, -1).astype(int)
)
.rename({
"RatingTomatometer": "tomatoes_rating",
"No. of Reviews": "tomatoes_votes",
}, axis="columns")
.drop(["Title"], axis="columns")
)
rotten_tomatoes_beta
Závorková odysea nekončí, někdo nám proaktivně do závorek nacpal i originální název naanglickojazyčných filmů. Pojďme se o tom přesvědčit pomocí metody .str.contains (protože tato metoda ve výchozím stavu používá pro vyhledávání regulární výrazy, které jsme se zatím nenaučili používat, musíme jí to explicitně zakázat argumentem regex=False):
rotten_tomatoes_beta[rotten_tomatoes_beta["title"].str.contains(")", regex=False)]
V rámci zjednodušení proto ještě odstraníme všechny takové závorky. K tomu pomůže funkce .str.rsplit, která rozdělí zprava řetězec na několik částí podle oddělovače a vloží je do seznamu - my za ten oddělovač zvolíme levou závorku "(", omezíme počet částí na jednu až dvě (n=1):
split_title = (
rotten_tomatoes_beta["title"]
.str.rsplit("(", n=1)
)
split_title.loc[[41, 61, 81]] # Některé seznamy obsahují jeden prvek, jiné dva
A jak teď vybrat první prvek z každého seznamu?
💡 Metoda apply umožňuje použít libovolnou transformaci (definovanou jako funkci) na každý řádek v tabulce či hodnotu v Series. Obvykle se bez ní obejdeme a měli bychom (proto se jí tolik speciálně nevěnujeme), protože není příliš výpočetně efektivní. Tady nám ale usnadní pochopení, co se vlastně dělá, t.j. vybírá první prvek nějakého seznamu:
def take_first(a_list): # Funkce, kterou použijeme v apply
return a_list[0]
rotten_tomatoes = (rotten_tomatoes_beta
.assign(
title=split_title.apply(take_first)
)
)
rotten_tomatoes
# Zbavení se duplikátů hned na začátku nám zachovalo filmy se stejným jménem :-)
rotten_tomatoes.query("title == 'The Magnificent Seven'")
pd.merge(
movies.dropna(subset=["year"]),
rotten_tomatoes,
on=["title", "year"],
how="inner"
)
Když sloučíme filmy a hodnocení na Rotten Tomatoes, z 947 filmů se nám skoro tři sta ztratí. Bohužel zde je na vině především nestejnost zápisu názvu, různé uřčité členy, interpunkce, podnázvy apod. Coby řešení se tady nabízí spousta a spousta manuální práce, případně nějaká heuristika, která by na sebe pasovala "hodně podobné" názvy.
Mimochodem, obtížnost manuální práce se mezi vývojáři někdy přeceňuje: Opravit 288 názvů filmů může být práce na hodinu až dvě, zatímco psát algoritmus na "řešení problému" může trvat stejně dlouho, ne-li déle.
Čtvrtý (a poslední) join
Dokončíme slučování všech čtyř tabulek:
movies_complete = pd.merge(
movies_with_rating_and_boxoffice,
rotten_tomatoes,
on=["title", "year"],
how="inner"
)
movies_complete.sort_values("boxoffice_rank").reset_index(drop=True)
A přišli jsme o dalších 175 filmů.
Co dál? Pokud by toto byl skutečný úkol, museli bychom se s tím nějak vypořádat - zkoumat, proč které řádky nesedí, v čem se liší názvy stejného filmu v různých datových sadách, jinými slovy manuální práce, práce, práce...
Naštěstí to je úkol jen ukázkový, a my můžeme být spokojeni, že máme sice neúplnou, ale přesto použitelnou datovou sadu :-)
Vztahy mezi dvěma proměnnými
Když jsme studovali vlastnosti zemí světa, věnovali jsme se především jednotlivým charakteristikám zvlášť, nanejvýš jsme si udělali intuitivní obrázek z bodového grafu ("scatter plot"), kde osy x a y patřily dvěma různým vlastnostem. Nyní se vztahy mezi více proměnnými budeme zabývat podrobněji a ukážeme si i některé odvážnější vizualizace.
Poznámka: Budeme pokračovat s výše uvedenými filmovými daty (a jejich sloučenými tabulkami), a tak je třeba, abys spustil/a všechny buňky předcházející této kapitole.
Co se týče vztahů mezi proměnnými, dost záleží na tom, jakého jsou typu. Tomu se podřizují zvolené typy grafů i vhodné statistické veličiny.
Dvě číselné proměnné
Minule jsme si ukázali, jak rychle získat přehled o vlastnostech jednotlivých numerických proměnných, tak si to zopákněme:
movies_complete.describe() # Tabulka základních statistických parametrů
movies_complete.hist(figsize=(12, 8), bins=30); # Histogram coby přibližná distribuční funkce

Nejjednodušším pohledem na dvě číselné proměnné je klasický bodový graf (.plot.scatter), který jsme si už ukazovali - hodnoty dvou proměnných tvoří hodnoty souřadnic. Pomocí něj se podíváme, jaký je vztah mezi počtem hodnotitelů a průměrným hodnocením na IMDb. Očekáváme, že na špatné filmy se "nikdo nedívá" (a málokdo je hodnotí), v čemž nám následující graf dává za pravdu:
movies_complete.plot.scatter(
x="imdb_rating",
y="imdb_votes",
c="black",
figsize=(7, 7),
logy=True
);

💡 Podobnou službu udělá i funkce seabornu scatterplot, jen neumí logaritmické měřítko sama o sobě.
Už při několika stovkách filmů nám ale začínají jednotlivé body splývat. Stejný graf pro všechny ohodnocené filmy (~200 000) bude vypadat už naprosto nepřehledně:
movies_with_rating.plot.scatter(
x="imdb_rating",
y="imdb_votes",
c="black",
figsize=(7, 7),
logy=True,
ylim=(10, 1e7)
);

Pro takové množství zřejmě bude vhodnější nějakým způsobem reflektovat spíš souhrnnou hustotu bodů než jednotlivé body jako takové. První možností je udělat body dostatečně "průhledné" (pomocí argumentu alpha) a velké (argument s), aby splývaly a výraznější barva odpovídala více bodům v témže okolí:
ax = movies_with_rating.plot.scatter(
x="imdb_rating",
y="imdb_votes",
c="black",
figsize=(7, 7),
s=50, # Velikost na "rozprostření"
logy=True,
alpha=0.002, # > 99% průhlednost
lw=0 , # bez okrajů
ylim=(10, 1e7)
)

Otázka (bez známé správné odpovědi): Proč je nespojitost v hodnocení cca u sta hodnotících?
Úkol: zkus vytvořit graf zobrazující vztah mezi hodnocením filmu a počtem hlasů na Rotten Tomatoes (tabulka rotten_tomatoes).
- Velikost grafu nastav dle uvážení.
- Barva bodů oranžová, body nastav bez okraje.
- Průsvitnost bodů
0.5.
Jak je možné tento graf interpretovat? Existuje vztah mezi hodnocením filmu (kolik % kritiků hodnotí film pozitivně) a počtem hlasů?
Jinou (a lepší) možností je "spočítat" dvourozměrný histogram, který místo binů "od-do" nabízí obdélníkové chlívečky ve dvou dimenzích. Poté ho lze vizualizovat pomocí teplotní mapy (heatmap) - každý obdélník se vybarví tím intenzivnější barvou, čím více hodnot do něj "spadlo". pandas ani seaborn tuto možnost jednoduše nenabízejí, ale matplotlib nabízí užitečnou funkci hist2d. Všimni si, že předáváme řady jako takové, nikoliv jejich názvy!
Při kreslení rovnou nastavíme dva klíčové argumenty:
range: obsahuje dvojice mezí v jednotlivých dimenzích (nadbytek závorek je tuple tuplů).cmap: barevná paleta použitá pro vyjádření hodnot, seznam možností jde nalézt v dokumentaci.
Poznámka: Není úplně jednoduché pracovat s histogramy v logaritmické škále, a proto si vybereme jinou dvojici proměnných (hodnocení na IMDb a rotten tomatoes):
plt.hist2d(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
range=((6.85, 9.05), (79.5, 101.5)),
bins=(11, 11),
cmap="Greens"
) # -> (data, hranice v první ose, hranice v druhé ose, objekt grafu)

Čím tmavší zelená, tím více filmů je v daném rozsahu.
Následující obrázek intuitivně vyjadřuje, jak body do chlívečků padají (vlevo trochu zamíchané body, vpravo spočítané obsahy chlívečků):
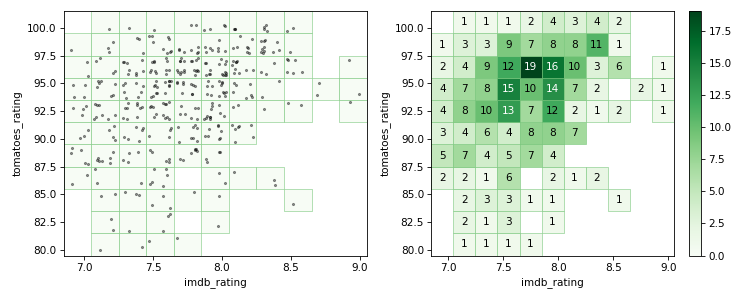
Kód (velmi volitelný) k vytvoření obrázku je v bonusovém materiálu
Úkol: Vytvoř graf z předcházejícího úkolu (vztah mezi hodnocením filmu a počtem hlasů na Rotten Tomatoes – tabulka rotten_tomatoes) ve formě dvourozměrného histogramu.
- Rozpětí hodnot pro hodnocení nastav od 70 do 100, rozpětí pro počet hlasů od 0 do 450.
- Vytvoř 6 binů pro hodnocení a 9 binů pro počet hlasů.
- Barvu grafu zvol oranžovou.
Biny nemusí být jenom pravoúhlé, ale pokud chceme poněkud méně diskriminovat různé směry, můžou se hodit biny šestiúhelníkové, které vykreslíš metodou .plot.hexbin:
movies_complete.plot.hexbin(
x="imdb_rating",
y="tomatoes_rating",
xlim=(7, 9),
ylim=(70, 100),
gridsize=40
)

Úkol: Také si zkus vytvořit graf pro hodnocení filmu a počet hlasů na Rotten Tomatoes se šestiúhelníkovými biny.
- Rozpětí hodnot na ose s hodnocením od 70 do 100.
- Počet šestiúhelníků
(25, 5), jestli je hodnocení na ose x,(5, 25)jestli je na ose y. - Barva grafu oranžová.
Který tvar binů se ti líbí víc?
Jinou možností, výpočetně náročnější, je odhadnout hustotu pravděpodobnosti výskytu filmů s danými souřadnicemi obou hodnocení. K tomu slouží tzv. jádrový odhad hustoty (kernel density estimate). Je to vlastně trochu sofistikovanější podoba splývání bodů, které jsme předvedli výše - kolem každého bodu se uvažuje pravěpodobnostní jádro, neboli kernel (typicky gaussovský), a výsledná pravděpodobnost je rovná součtu kernelů v daném místě souřadnicové soustavy.
V seabornu k tomu slouží funkce kdeplot - v jednorozměrném případě kreslí křivku, v dvourozměrném umí vykreslit buď "vrstevnice", nebo plochy různě intenzivní barvou podle spočítané hustoty pravděpodobnosti.
ax = sns.kdeplot(
x=movies_complete["imdb_rating"],
y=movies_complete["tomatoes_rating"],
n_levels=15, # Počet úrovní intenzity
shade=True, # Nechceme jen "vrstevnice", ale barevnou výplň
bw_method=.06 # Magický faktor pro míru "rozpití"
)
# Ještě si pomocí matplotlibu upravíme rozsahy os
ax.set_xlim(7, 9)
ax.set_ylim(70, 100);

Úkol: Na datech pro hodnocení filmu a počet hlasů na Rotten Tomatoes vytvořme také graf s jádrovým odhadem hustoty (kde).
- Rozpětí hodnot pro hodnocení filmu opět od 70 do 100.
- Počet úrovní intenzity 10.
- Graf bude mít barevnou výplň, ne jenom vrstevnice.
- Barva grafu oranžová.
Funkce seabornu zvaná jointplot umí velice elegantně vytvořit kombinovaný graf obsahující:
sdružené rozdělení v podobě čtvercového grafu některého z výše uvedených typů (jeho jméno přijde do argumentu
kind) pro vztah obou proměnných.marginální rozdělení v obou proměnných nezávisle (malé histográmky nebo jádrové odhady hustoty po stranách)
sns.jointplot(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
kind="scatter",
color="#4CB391",
xlim=(6, 9),
ylim=(70, 100),
alpha=.5
);

sns.jointplot(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
kind="kde",
color="#4CB391",
n_levels=15,
shade=True,
xlim=(7, 9),
ylim=(70, 100),
joint_kws = {"bw_method": .1}
);

Úkol: Na závěr ještě zkus vytvořit kombinovaný graf jointplot. Jako podkladová data opět využij hodnocení filmu a počet hlasů na Rotten Tomatoes.
- Druh grafu nastav
kdeneboscatter. - Barva grafu oranžová.
- Rozpětí hodnot pro hodnocení opět od 70 do 100.
- 10 úrovní intenzity pro
kdenebo průsvitnost 0.5 proscatter.
Který z prezentovaných grafů se ti líbí nejvíc? Proč?
Korelace (a nikoliv kauzalita)
Máme-li dvě proměnné, obvykle nás zajímá, jak spolu souvisejí. Jestli ze změny jedné můžeme usuzovat na změnu druhé a naopak. V tomto smyslu rozlišuje dva základní úrovně vztahu:
Korelace mezi dvěma proměnnými znamená, že pokud se jedna z nich mění, mění se nějakým způsobem i druhá, a to v míře, kterou dokážeme alespoň částečně odhadnout. Není řečeno (obvykle to ani nejde), jestli jde o vztah příčinný (jedním, nebo druhým směrem), nebo jestli jsou třeba obě proměnné jen závislé na nějakém třetím faktoru.
Kauzalita naproti tomu znamená, že jedna proměnná je opravdu závislá na druhé, a tedy že cílenou změnou první můžeme přivodit změnu druhé.
Statistickými metodami je velice snadné prokázat korelaci, naopak je velice obtížné až nemožné ze samotných čísel vykoukat kauzalitu - to většinou vyžaduje hlubší znalost kontextu a cílené experimentování, nikoliv jen pozorování.
My si můžeme říct, jak spolu souvisí (jaká je korelace mezi nimi) hodnocení na IMDb a Rotten Tomatoes, ale těžko z čísel vyčteme, jestli se navzájem ovlivňují (aniž bychom se ptali hlasujících, na základě čeho se rozhodovali). Nejspíš selským rozumem dojdeme k tomu, že z hlediska kauzality jsou obě hodnocení nezávislá a že za případnou korelaci může spíše třetí faktor, tj. "jak se film povedl".
Korelační koeficient
Ve světě statistiky míru korelace obvykle vyjadřujeme pomocí korelačního koeficientu. To je bezrozměrné číslo od -1 do 1, přičemž 0 znamená naprostou nezávislost, 1 značí, že jakákoliv změna v jedné veličině je provázena stejně významnou změnou ve veličině druhé, -1 pak značí změnu stejně významnou, ale v opačném směru.
Existuje několik metod výpočtu korelačního koeficientu. Pandas umí v základu tři, z nich si ukážeme jen ten výchozí, Pearsonův, který je ideální pro odhalení lineárních vztahů.
Následující obrázek ukazuje typické hodnoty korelačního koeficientu pro různá rozdělení dvou proměnných:
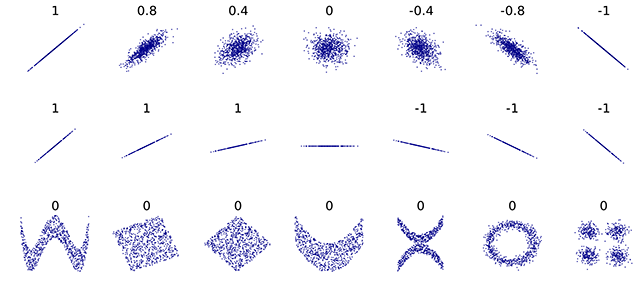
Obrázek převzat z wikipedie.
{kind=link}
Výpočet korelačního koeficientu mezi dvěma Series se v pandas provede zavoláním metody .corr:
movies_complete["imdb_rating"].corr(movies_complete["tomatoes_rating"])
Číslo 0,667 ukazuje na poměrně silný vztah - čím lepší hodnocení na jednom serveru, tím lepší hodnocení na serveru druhém.
Kompletní tabulku korelačních koeficientů mezi všemi sloupci v tabulce získáš metodou .corr na tabulce samotné:
movies_complete.corr(method="pearson") # Jsme explicitní ohledně typu koeficientu
Co je z tabulky vidět?
- každá proměnná plně koreluje sama se sebou (1,0)
- nelze spočítat korelační koeficient
is_adult, protože tento sloupec obsahuje jen jednu hodnotu - jak jsme již zmiňovali, hodně korelují hodnocení na IMDb a na Rotten Tomatoes
- čím více hlasů na IMDb, tím obvykle lepší hodnocení (kdo by se díval na špatné filmy?), vyšší celkový zisk v kinech (kdo by hodnotil, kdyby film nikdo neviděl?)
- možná překvapí silná korelace počtu hodnocení na Rotten Tomatoes a roku premiéry (je to tím, že se filmově-kritické weby množí jako houby po dešti?)
A mnoho dalšího...
Varování: Velký (kladný nebo záporný) korelační koeficient téměř vždy značí nějaký (zejména lineární či aspoň monotónní) vztah mezi proměnnými. Opačně to ovšem neplatí - korelační koeficient blízký nule může zahrnovat jak případy naprosté nezávislosti, tak situace, kdy vztah mezi proměnnými je komplexnějšího charakteru, jak je vidět v dolním řádku obrázku výše.
Dovedeno do extrému, není vůbec problém nakreslit téměř libovolně vypadající obrázek alias bodový graf, který bude mít dané souhrnné statistiky (tedy naivně pohlíženo "bude stejný"). V pěkném interaktivním článku Same Stats, Different Graphs... autoři ukazují pěkné animace plynulých přechodů mezi naprosto odlišně vyhlížejícími sadami, aniž by se změnila kterákoliv ze základních statistik včetně korelací.
Pokud chceě najednou zobrazit vztahy všech dvojic různých numerických proměnných, může se hodit funkce pairplot, která vykresli čtvercovou mřížku s histogramy na diagonále a dvourozměrnými grafy (ve výchozím nastavení bodovými) mimo diagonálu:
sns.pairplot(movies_complete[["year", "imdb_rating", "imdb_votes", "tomatoes_rating", "lifetime_gross"]])

Dvě kategorické proměnné
Protože máme kategorických proměnných v tabulkách o filmech málo, musíme si je vyrobit. A přitom se naučíme další dva triky.
První trik: Kategorická proměnná z číselné
Vezmeme rok premiéry filmu a přiřadíme mu dekádu pomocí funkce cut. Tato funkce vezme nějakou číselnou Series a hranice binů ("chlívečků", stejně jako u histogramu) a každou hodnotu označí příslušným intervalem (jeho dolní a horní hranicí):
pd.cut(
movies_with_rating["year"],
bins=range(1890, 2021, 10) # 1890, 1900, 1910, ..., 2020
)
To je přesné, ale nepříliš estetické. Takže provedeme ještě jednu úpravu - z intervalu pomocí metody apply a námi definové funkce uděláme hezké označení dekády ((1980, 1990] nahradíme řetězcem "1980s").
def interval_to_decade_name(interval):
"""Převede (1980, 1990] na 1980s apod."""
return str(interval.left)+"s"
pd.cut(
movies_with_rating["year"],
bins=range(1890, 2021, 10)
).apply(interval_to_decade_name)
💡 V pravém smyslu dekáda není kategorickou, ale ordinální proměnnou, protože má přirozené řazení, ale nic nám nebrání s ní jako s kategorickou zacházet.
Druhý trik: Kategorická proměnná ze seznamu hodnot
Sloupec genres je velice užitečný, ale protože obsahuje různé kombinace hodnot, navíc oddělených čárkou v řetězci, s ním samotným toho moc nepořídíme. Potřebujeme proto skupiny žánrů rozhodit do nezávislých řádků (každý film se nám pak v tabulce opakovat tolikrát, do kolika různých žánrů patří). K tomu použijeme metody str.split (rozděluje řetězec na seznam podle nějakého oddělovače) a explode (zkopíruje řádek pro každou jednotlivou položku seznamu v nějakém sloupci):
(movies_with_rating["genres"]
.str.split(",") # řetězec -> seznam
.explode() # zkopíruje řádky => pro každý žánr jednu kopii
)
Toto je pravověrná kategorická proměnná. Pojďme si tedy sestavit tabulku, která obsahuje obě:
decades_and_genres = (
movies_with_rating.assign(
decade = pd.cut(
movies_with_rating["year"],
bins=range(1890, 2021, 10)
).apply(interval_to_decade_name),
genres = movies_with_rating["genres"].str.split(",")
)
.rename({"genres": "genre"}, axis="columns")
.explode("genre")
)[["title", "genre", "decade", "imdb_rating", "imdb_votes"]]
decades_and_genres
U dvou kategorických proměnných nás obvykle zajímá, jak často se vyskytuje jejich kombinace - v našem případě tedy kolik filmů daného žánru bylo natočeno v které dekádě. Toto přesně dělá funkce crosstab:
decades_vs_genres = pd.crosstab(
decades_and_genres["decade"], # Co se použije jako řádky
decades_and_genres["genre"], # Co se použije jako sloupce
)
Případně nemusíme zkoumat jenom počet, může nás zajímat i jiná agregace - v tom případě musíme uvést argumenty values (na čem se agregace bude provádět) a aggfunc (jaká agregační funkce se použije).
Zkusme tedy např. průměrné hodnocení jednotlivých žánrů v dané dekádě (že by se dokumentání filmy lepšily a horory horšily?):
decades_vs_genres_rating = pd.crosstab(
index=decades_and_genres["decade"],
columns=decades_and_genres["genre"],
values=decades_and_genres["imdb_rating"],
aggfunc="mean"
)
decades_vs_genres_rating[["Documentary", "Horror"]] # Vybereme dva zajímavé sloupce
Pokud si chceme hodnoty z .crosstab, můžeme si nakreslit teplotní mapu (podobně jako dříve u dvourozměrných histogramů) pomocí funkce heatmap:
sns.heatmap(decades_vs_genres);

Toto jednoduché zobrazení asi není příliš přehledné, proto zkusíme přidat trochu estetiky. Většinu popsaných argumentů najdeš v dokumentaci a okomentovanou přímo v kódu, širší komentář (zejména k barevné paletě) pro "jednoduchost" vynecháme:
from matplotlib.colors import LogNorm
# Vytvoříme si škálu hodnot rovnoměrnou v logaritmickém měřítku
# Tato škála se pakkterá bude mapovat
log_norm = LogNorm(
vmin=1, # Kde škála začíná
vmax=decades_vs_genres.max().max(), # Kde škála končí
)
_, ax = plt.subplots(figsize=(18,5.5)) # Vytvoříme dostatečně veliký graf
sns.heatmap(
decades_vs_genres,
ax=ax, # Kreslíme do připraveného objektu `Axes`
vmin=1, # Ignorujeme nulové hodnoty (nejdou logaritmovat!)
linewidths=1, # Oddělíme jednotlivá okénka
annot=True, # Chceme zobrazit hodnoty
fmt="d", # Zobrazíme hodnoty jako celá čísla
norm=log_norm, # Použijeme škálování
cmap="PuBu", # Vybereme si barevnou paletu
cbar=False, # Schováme barevný proužek vpravo, nepotřebujeme ho
);
ax.set_ylim(13, 0); # Obcházíme oříznutí, které je asi bug seabornu

Prakticky vzato se pak tato vizualizace nachází někde na pomezí tabulky a grafu.
Kategorická a číselná proměnná
Když se zkoumají vztahy kategorických a numerických proměnných, koukáme se vlastně na sadu numerických proměnných, vyhodnocovaných pro každou hodnotu kategorické proměnné zvlášť. V našem případě tedy pro horory zvlášť, pro dokumenty zvlášť apod. Z výpočetního hlediska je toto téma pro shlukování a operaci groupby, kterým se detailně věnuje příští hodina. Nyní si jen ukážeme některé pěkné vizualizace.
Krabicový graf si jistě pamatuješ z minula, pomocí seabornu ho vytvoříš zavoláním funkce boxplot - jen se nekreslí krabičky pro různé proměnné, ale pro tutéž číselnou proměnnou, jen v závislosti na hodnotě proměnné kategorické:
_, ax = plt.subplots(figsize=(12, 5)) # boxplot neumí specifikovat velikost grafu
sns.boxplot(data=decades_and_genres,
x="decade",
y="imdb_rating",
ax=ax) # kam se bude kreslit

Vedle toho "strip plot" (funkce stripplot) znázorňuje každou hodnotu tečkou, vysázenou ve sloupci nad příslušnou kategorií (ve správné výšce, nicméně přesné horizontální umístění nenese žádnou informaci):
_, ax = plt.subplots(figsize=(12, 5)) # stripplot neumí specifikovat velikost grafu
sns.stripplot(
data=decades_and_genres,
x="decade",
y="imdb_rating",
s=1,
ax=ax);

Velice podobnou roli jako krabicový graf hraje houslový ~plot~ graf, který místo čtverců nabízí miniaturní křivku hustoty pravděpodobnosti (resp. jádrový odhad). Vykreslíš ho funkcí violinplot:
_, ax = plt.subplots(figsize=(12, 5)) # violinplot neumí specifikovat velikost grafu
sns.violinplot(
data=decades_and_genres,
x="decade",
y="imdb_rating",
ax=ax)

Vztahy mezi více proměnnými
Pokud si tyto materiály nečteš na holografickém displeji, jsi při zobrazování dat omezen/a na dva rozměry. Můžeš si prohlížet dvourozměrné tabulky, kreslit dvourozměrné grafy. Interaktivní knihovny pro vizualizaci dat ti pomocí posuvníků umožní prohlížet si různé jednorozměrné nebo dvourozměrné řezy vícerozměrných vztahů.
Matplotlib i plotly umějí vykreslovat 3D grafy, tak se tím můžeš inspirovat, ale není to moc praktické.
💡 V jistém smyslu jsme si už předminule ukázali, jak třetí a čtvrtý rozměr do dvourozměrného grafu přeci jen propašovat - pomocí barvy a velikosti symbolu. Ne vždy je to snadné a přehledné, ale v některých situacích je to dobrá volba.
3D grafy (nepovinné až zbytečné)
Pokud chceš v matplotlibu kreslit trojrozměrné grafy, musíš si síť souřadnic vytvořit specifickým způsobem.
from mpl_toolkits.mplot3d import Axes3D # Import, bez kterého nebude následující fungovat
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')

Potom už se zbylá volání budou chovat podobně jako ve dvou rozměrech:
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
movies_complete["lifetime_gross"])
ax.set_xlabel("IMDb rating")
ax.set_ylabel("Rotten Tomatoes rating")
ax.set_zlabel("Gross (total)");

Graf je to poněkud statický a třetí rozměr nám uniká (a ani 3D brýle nepomohou).
Pokud kreslíš grafy mimo jupyter notebook a máš například nainstalovaný framework Qt, můžeš si grafy z matplotlibu prohlížet i interaktivně, což v tomto případě je velice užitečné.
Naproti tomu uvnitř notebooku v notebooku je výrazně efektivnější použít plotly (resp. plotly.express):
# Toto nemusí fungovat všem, můj prohlížeč si stěžuje na chybějící WebGL
import plotly.express as px
fig = px.scatter_3d(movies_complete, x="imdb_rating", y="tomatoes_rating", z="lifetime_gross", hover_name="title")
fig.show()
Bonusový materiál
Obrázek ilustrující plnění 2D histogramu:
import numpy as np
import physt
np.random.seed(42)
limits=((6.85, 9.05), (79.5, 101.5))
bins=(11, 11)
# Ve phystu vytvoříme objekt 2D histogramu
h2 = physt.h2(
movies_complete["imdb_rating"],
movies_complete["tomatoes_rating"],
bins=bins,
range=limits,
)
# Chceme ne jeden, ale dva grafy vedle sebe!!!
fig, ax = plt.subplots(1, 2, figsize=(10,4))
##### levý graf
# Vykreslíme si histogram, ale schováme ho
h2.plot(
cmap="Greens", # Paleta, kterou použijeme v pravém grafu
cmap_min=0,
cmap_max=1e9, # Zajistíme si, že všechy biny budou mít první barvu palety
show_zero=False, # Nenakreslí se nám prázdné biny
ax=ax[0], # Nakreslíme do levého podgrafu
show_colorbar=False, # Nepotřebujeme legendu k paletě
zorder=-1, # Schováme za následující scatterplot
#alpha=0,
)
# Scatterplot překreslený přes "histogram" s body mírně rozházenými, aby se daly spočítat
ax[0].scatter(
movies_complete["imdb_rating"] + np.random.uniform(-.03, .03, len(movies_complete["imdb_rating"])),
movies_complete["tomatoes_rating"]+ np.random.uniform(-.3, .3, len(movies_complete["imdb_rating"])),
s=4,
color="black",
alpha=0.4,
)
ax[0].set_xticks([7.0, 7.5, 8.0, 8.5, 9.0])
##### Pravý graf ukazuje, kolik bodů spadlo do kterého obdélníku
# Tady už použijeme vykreslování histogramů
h2.plot(
show_values=True, # Chceme v binech zobrazit čísla
cmap="Greens",
show_zero=False,
ax=ax[1], # Kreslíme do pravéoho podgrafu
show_colorbar=True # Chceme ukázat legendu k paletě
)
# Uložíme obrázek s dostatečným rozlišením
fig.savefig("static/plneni_2d_hist.png", dpi=75)