Analýza časových řad
V této lekci se podíváme na to, jak analyzovat časové řady. Na pomoc si pro tento účel vezmeme data s údaji o počasí (teplota, tlak apod.).
Abychom s daty mohli efektivně pracovat, budeme muset data ještě transformovat a pročistit. To je (bohužel) běžnou součástí datové analýzy, protože zdrojová data jsou typicky ne zcela vhodně uspořádána a často obsahují i chyby. Při práci s časovými řadami využijeme bohaté možnosti pandas pro práci s časovými údaji.
V této lekci se naučíš:
- načítat data ze souborů ve formátu Excel,
- efektivně čistit a transformat data na "spořádaná data".
Instalace knihovny xlrd
Knihovna xlrd dodá Pandasu schopnost pracovat se soubory ve formátu Excel.
# %pip install xlrd
Načtení knihoven
Budeme používat samozřejmě pandas, pro vizualizaci pak matplotlib a seaborn.
%matplotlib inline
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
Příprava dat
Načtení hrubých dat - počasí
Naší základní datovou sadou budou data o počasí, konkrétně v Praze-Ruzyni. Data poskytuje Českým hydrometeorologický ústav (ČHMÚ) ve formě Excel souborů, dostupných z http://portal.chmi.cz/historicka-data/pocasi/denni-data.
Možná překvapivě není úplně snadné dobrá a podrobná data získat. Ta nejkvalitnější jsou placená, navíc "Česká data o počasí patří k nejdražším". Jen nedávno soud nařídil poskytovat alespoň základní data zdarma, viz článek na irozhlas.
Takto vypadají náhledy dvou listů ze souboru P1PRUZ01.xls, který obsahuje historická data z meteorologických měření v Praze-Ruzyni. Data jsou poměrně nepěkně uspořádána. Ani v Excelu by se s těmito soubory nepracovalo dobře...
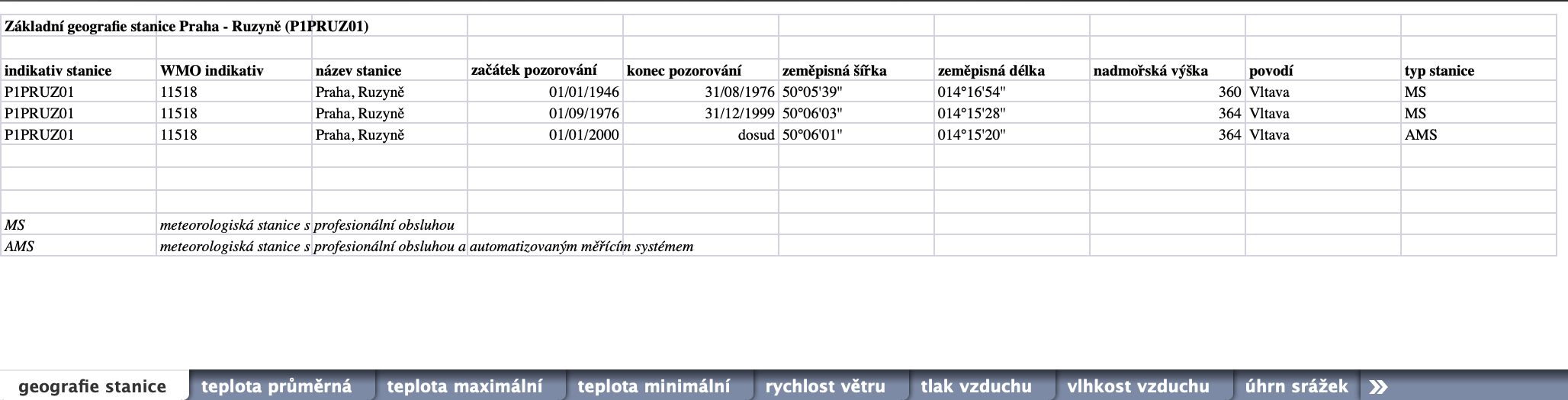
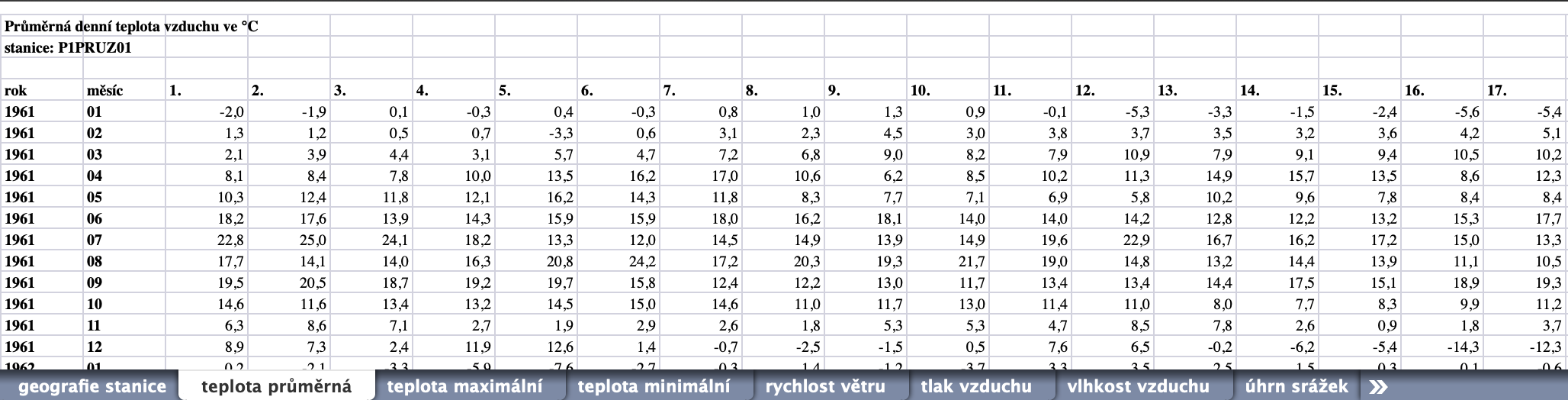
Samotné načtení souboru je poměrně snadné. Použijeme na to třídu ExcelFile, protože kromě načítání poskytuje také property sheet_names.
Často stačí (a je jednodušší) použít funkci read_excel. V dokumentaci si všimni velkého množství argumentů, které umožňují správně načíst všelijak formátované soubory a hodnoty v nich.
RUZYNE_DATA_FILENAME = "P1PRUZ01.xls"
RUZYNE_DATA_URL = "https://data4pydata.s3-eu-west-1.amazonaws.com/pyladies/P1PRUZ01.xls"
# stáhne data pokud ještě nejsou k dispozici
import os
import urllib.request
def save_file_from_url(url, target_filename):
if not os.path.isfile(target_filename):
print("Stahuji data - počkej chvíli ...")
urllib.request.urlretrieve(url, target_filename)
print(f"Data jsou v souboru {target_filename}")
save_file_from_url(RUZYNE_DATA_URL, RUZYNE_DATA_FILENAME)
# otevření Excel souboru
excel_data_ruzyne = pd.ExcelFile(RUZYNE_DATA_FILENAME)
Zobrazíme si seznam listů v souboru.
excel_data_ruzyne.sheet_names
Zatím jsme žádná data nenačetli (nemáme žádný DataFrame s daty ze souboru). Data načte ve formě DataFrame až metoda parse.
# načti data z jednoho listu a zobraz prvních 5
teplota_prumerna = excel_data_ruzyne.parse("teplota průměrná")
teplota_prumerna.head(5)
Výsledek není přesně to, co bychom chtěli. Náprava je ale naštěstí jednoduchá - potřebujeme jen přeskočit první tři řádky. K tomu stačí přidat skiprows=3.
teplota_prumerna = excel_data_ruzyne.parse("teplota průměrná", skiprows=3)
teplota_prumerna.head(5)
Tohle vypadá už trochu lépe - řádky a sloupce jsou tak, jak bylo zamýšleno. Problémem ale je, že dny jsou jako sloupce. Už jen proto, že ne každý měsíc má 31 dní. Proto se v posledních třech sloupcích vyskytují nedefinované hodnoty neboli NaN (Not a Number).
Chybějící hodnoty se mohou vyskytnout i z jiných důvodů než "jen" kvůli nevhodnosti uspořádání dat. Např. měřící přístroj mohl mít závadu, data se poškodila apod. Pro chybějící hodnoty mohou být použity různé zkratky a symboly a právě proto existuje šikovný argument na_values.
Z mnoha dobrých důvodů, které sami uvidíte v praxi, je naším cílem dostat data do podoby tzv. tidy data, kdy řádky odpovídají jednotlivým pozorováním (měřením), názvy sloupců odpovídají veličinám.
Tady přijde vhod metoda melt. Ta slouží právě pro případy, kdy hodnoty jsou zakódované jako názvy sloupců. Takto vysvětlíme melt, že sloupce ["rok", "měsíc"] jsou už správně jako "veličiny", že v názvech zbývajících sloupců jsou hodnoty veličiny den a že hodnoty patří veličině teplota průměrná, což se použije pro pojmenování nového sloupce.
teplota_prumerna_tidy = teplota_prumerna.melt(
id_vars=["rok", "měsíc"], var_name="den", value_name="teplota průměrná"
)
teplota_prumerna_tidy.head(5)
V tomto případě bylo celkem jasné, že názvy sloupců jsou vlastně hodnoty nějaké veličiny. Někdy to může být více skryté, např. v případě kategorických proměnných. Třeba data z měření délky nohou můžeme dostat v tomto formátu:
leg_length = pd.DataFrame({"left": [81, 81.4], "right": [78.2, 78]})
leg_length
Úkol: Má leg_length podobu tidy data? Pokud ne, dokážeš tato data uspořádat správně?
Vytvoření "správného" (časového) indexu
Téměř nikdy nechceme pracovat s oddělenými sloupci "rok", "měsíc" apod. Práci s časovými údaji a časovými řadami mají na starosti specializované třídy, především Timestamp a DatetimeIndex, pro rozdíly mezi časovými údaji pak Timedelta. Přehled najdeš v dokumentaci: Time series / date functionality. A věřte - není to jednoduchý problém. Časová algebra pracuje zároveň s desítkovou, šedesátkovou, dvanáctkovou, dvacetčtyřkovou, sedmičkovou, měsíční, kvartální, roční, ... algebrou. Do toho vstupují časové zóny, přestupné roky, letní čas, různé kalendáře a kdo ví co ještě.
Pojďme tedy vytvořit pro naši časovou řadu ten "správný" časový index. K tomu se často se hodí funkce to_datetime. Tato funkce umí převádět numerické nebo textové údaje (jednotlivě i celé řady) do toho správného Pandas typu pro práci s časovými údaji.
Pro nás se hodí, že umí pracovat i s daty, kde jsou v oddělených sloupcích roky, měsíce, dny atd. Ukážeme si to na na jednoduchém příkladu.
# příklad řady datumů v oddělených sloupcích
split_dates_example = pd.DataFrame(
{"year": [2015, 2016], "month": [2, 3], "day": [4, 5]}
)
split_dates_example
Funkce to_datetime nám z ukázkové tabulky vytvoří řadu (Series) typu datetime64[ns]. Tento (numpy) typ podporuje mnoho užitečných metod pro práci s časovými údaji, viz. Datetimes and Timedeltas. Údaj [ns] ukazuje na (výchozí) nanosekundovou přesnost.
pd.to_datetime(split_dates_example)
Aby to fungovalo na naše česká data, je potřeba jen přejmenovat sloupce "rok", "měsíc", "den" na "year", "month", "day". K tomu máme metodu rename, tak to pojďme vyzkoušet rovnou dohromady. Výsledek uložíme do nové proměnné datum.
datum = pd.to_datetime(
teplota_prumerna_tidy[["rok", "měsíc", "den"]].rename(
columns={"rok": "year", "měsíc": "month", "den": "day"}
),
)
Skoro - skončilo to poměrně logickou chybou (výjimkou) ValueError: cannot assemble the datetimes: day is out of range for month. Nepovedlo se (naštěstí) přesvědčit pandas, že všechny měsíce mají 31 dní :)
Pomocí errors="coerce" ale můžeme nařídit, aby se převedla všechna správná data a chybná data se označila jako NaN, resp. v tomto případě NaT - Not a Time.
datum = pd.to_datetime(
teplota_prumerna_tidy[["rok", "měsíc", "den"]].rename(
columns={"rok": "year", "měsíc": "month", "den": "day"}
),
errors="coerce",
)
datum
Pro úplnou informaci o čase bychom měli ještě přidat údaj o časové zóně. To nám umožní správně časy porovnávat, nebo třeba zachytit letní a zimní čas, což je často dosti svízelný problém. V našem případě denních dat to sice není zcela zásadní, v některých případech se to ale projevit může.
U časových údajů, které neobsahují časovou zónu, můžeme použít .dt.tz_localize. Pro konverzi časové zóny pak slouží .dt.tz_convert.
.dt je tzv. accessor object pro práci s časovými vlastnostmi dat.
datum_localized = datum.dt.tz_localize("Europe/Prague")
datum_localized
Určitě jste si všimli, že přibyl i údaj o čase, a samozřejmě o časové zóně a tím i o posunu od UTC. +01:00 znamená +1 hodina od UTC. U datumů je totiž koncept časové zóny ne úplně přirozený a proto Pandas přidal i čas (00:00:00). Jelikož je ale často význam denních dat nějaký souhrn za konkrétních 24 hodin (a někdy za 23 hodin a někdy za 25 hodin díky střídaní letního a zimního času), je lepší pracovat i konkrétním časem (začátkem dne). A to je i náš případ.
Teď už jen pomocí assign přidáme sloupec "datum". Můžeš ověřit, že následná analýza bude fungovat i s lokalizovaným časem datum_localized.
teplota_prumerna_tidy = teplota_prumerna_tidy.assign(datum=datum)
teplota_prumerna_tidy
Úkol: to_datetime dokáže pracovat i s řetězci, což se často hodí. Převeďte ladies_times na vhodný typ pro časové údaje, přiřaďte naši časovou zónu a poté pomocí tz_convert převeďte na UTC. Možná budete muset pandám vysvětlit, že v Česku jsou v datumech nejdříve dny, na rozdíl třeba od Ameriky. Naštěstí na to stačí jeden jednoduchý argument pro to_datetime.
ladies_times = ["23. 1. 2020 18:00", "30. 1. 2020 18:00", "6. 2. 2020 18:00"]
# pandas_times = pd.to_datetime(___).___.___
Čištění dat
Chybějící data jsou v našem případě důsledkem nehezkého uspořádání zdrojového Excelu, takže s jejich opravou si nebudeme lámat hlavu a rovnou přistoupíme k jejich smazání.
teplota_prumerna_tidy_clean = teplota_prumerna_tidy.dropna()
Úkol: Zařaďte dropna do sestrojení datumů tak, abychom nemuseli použít errors="coerce" pro to_datetime.
# odkomentujte a přidejte dropna
# pd.to_datetime(
# teplota_prumerna_tidy[["rok", "měsíc", "den"]].rename(
# columns={"rok": "year", "měsíc": "month", "den": "day"}
# ),
# )
Úkol: Vytvořte teplota_prumerna_tidy_clean_indexed se sloupcem datum jako indexem a bez sloupců rok, měsíc a den. Můžete použít metodu drop.
teplota_prumerna_tidy_clean_indexed = ___
Vše dohromady
Parsování celého souboru, tj. jeho načtení a převedení do požadované formy Pandas DataFrame, máme teď hotové. Pro další generace (a naše použití) na to definujeme funkci. V rámci této funkce také vyhodíme sloupce rok, měsíc a den, sloupec datum použijeme jako index a data podle datumu setřídíme. Přidali jsme ještě jméno listu jako vstupní parameter, což se bude hodit hned vzápětí pro načítání všech listů do jednoho DataFrame.
def extract_and_clean_chmi_excel_sheet(excel_data, sheet_name):
"""Parse ČHMÚ historical meteo excel data"""
# načti list z excel souboru a převeď na tidy data formát
data_tidy = (
excel_data.parse(sheet_name, skiprows=3)
.melt(id_vars=["rok", "měsíc"], var_name="den", value_name=sheet_name)
.dropna()
)
# vytvoř časovou řadu datumů
datum = pd.to_datetime(
data_tidy[["rok", "měsíc", "den"]].rename(
columns={"rok": "year", "měsíc": "month", "den": "day"}
)
)
# přidej sloupec datum jako index a odstraň den, měsíc, rok a vrať setříděný výsledek
return (
data_tidy.assign(datum=datum)
.set_index("datum")
.drop(columns=["rok", "měsíc", "den"])
.sort_index()
)
A teď už si můžeme načíst všechna data z Ruzyně tak, jak se nám budou hodit pro analýzu.
# otevři Excel soubor
excel_data_ruzyne = pd.ExcelFile("P1PRUZ01.xls")
# načti všechny listy kromě prvního
extracted_sheets = (
extract_and_clean_chmi_excel_sheet(excel_data_ruzyne, sheet_name)
for sheet_name in excel_data_ruzyne.sheet_names[1:]
)
# spoj všechny listy do jednoho DataFrame
ruzyne_tidy = pd.concat(extracted_sheets, axis=1)
U použití concat je důležité, že všecha data mají stejný index. axis=1 říká, že se mají skládat sloupce vedle sebe. Výchozí axis=0 by spojovala data pod sebe a nedopadlo by to úplně dobře (můžeš vyzkoušet :)). Detailněji jsme to řešili v lekci o nulových hodnotách a odlehlých pozorováních.
Prohlédneme si výslednou tabulku ruzyne_tidy.
ruzyne_tidy
Indexování a výběr intervalů
Data, která jsme načetli a vyčistili, tvoří vlastně několik časových řad v jednotlivých sloupcích tabulky ruzyne_tidy. Granularita (nebo frekvence či časové rozlišení) je jeden den.
Pomocí to_period() bychom mohli datový typ indexu převést i na period[D]. To může zrychlit některé operace, pro naše použití to ale není nezbytné.
ruzyne_tidy.index.to_period()
Už jsme si ukazovali indexování (výběr intervalu) pomocí .loc. U časových řad to funguje samozřejmě také. Pozor na to, že .loc vrací data včetně horní meze, na rozdíl od indexování listů nebo numpy polí.
Konkrétní období můžeme vybrat třeba takto:
ruzyne_tidy.loc[pd.Timestamp(2017, 12, 24) : pd.Timestamp(2018, 1, 1)]
Atributy časových proměnných
Časové proměnné typu DatetimeIndex poskytují velice užitečnou sadu atributů vracející
- části časového údaje, např.
.yearvrátí pouze rok,.monthměsíc apod., - relativní informace , např.
.weekdaynebo.weekofyear - kalendářní vlastnosti jako
is_quarter_startnebois_year_end, které by bylo poměrně náročné zjišťovat numericky.
ruzyne_tidy.index.year
Můžeme tak vybrat jeden celý rok např. takto:
ruzyne_tidy.loc[ruzyne_tidy.index.year == 2018]
Nebo můžeme získat data pro všechny dny před rokem 1989, které jsou začátky kvartálů a zároveň to jsou pondělky.
ruzyne_tidy.loc[
ruzyne_tidy.index.is_quarter_start
& (ruzyne_tidy.index.weekday == 0)
& (ruzyne_tidy.index.year < 1989)
]
Úkol: Jaká byla průměrná teplota první (a jedinou) neděli v roce 2010, která byla zároveň začátkem měsíce? Pokud máte řešení a čas, zkuste vymyslet aternativní způsob(y).
# ruzyne_tidy.loc[
# ___
# & (___)
# & (___),
# "teplota průměrná",
#]
Práce s časovou řadou
Pojďme trochu zkombinovat statistiku a práci s časovou řadou. Zajímalo by vás, jak moc byl který rok teplý či studený? Pomocí resample můžeme změnit rozlišení dat na jiné období, např. jeden rok.
ruzyne_yearly = ruzyne_tidy.resample("1Y")
Co že jsme to vlastně vytvořili?
ruzyne_yearly
Dostali jsme instanci třídy DatetimeIndexResampler. To zní logicky, ale kde jsou data? Ta zatím nejsou, protože jsme ještě pandas neřekli, jak vlastně mají ze všech těch denních údajů v rámci jednoho roku vytvořit ta roční data. Neboli, jak data agregovat.
Ze statistiky víme, že jedním z ukazatelů může být střední hodnota. Zkusíme vypočítat průměrnou "teplotu průměrnou" (není to překlep) a rovnou vykreslit.
ruzyne_yearly["teplota průměrná"].mean().plot();

Trochu podobnou operací jako resampling je rolování. To spočívá v plynulém posouvání "okna", které slouží pro (vážený) výběr dat a následné aplikaci agregační funkce (jako u resample). Pojďme pomocí rolling vytvořit podobný pohled na roční průměrnou teplotu. Rozdíl oproti resample je v tom, že dostaneme pro každý den jednu hodnotu, nikoli jen jednu hodnotu pro celý rok. A také už nemůžeme použít interval "1Y", protože jeden (kalendářní) rok není dobře definovaný interval díky přestupným rokům.
ruzyne_tidy["teplota průměrná"].rolling("365.25D", min_periods=365).mean().plot();

Pro podrobnější přehled práce s časovými řadami se podívejta např. na https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html nebo třeba na hezký článek s podobnými daty https://www.dataquest.io/blog/tutorial-time-series-analysis-with-pandas/.
Úkol: Navrhněte vhodnou agregaci pro maximální teplotu (ne průměr) a vykreslete.
# ruzyne_yearly[___].___().___();
Úkol: Převzorkujte údaje za rok 2018 po měsících. Jaký měsíc měl nejvíc srážek, tj. za jaký byl součet sloupce "úhrn srážek" nejvyšší?
# doplňte nebo vyřešte po svém :)
# ruzyne_tidy.loc[___ == 2018, "úhrn srážek"].___(
# "1M"
# ).___().___(ascending=False).index[___].___